Attention is all you need
2025-04-13
In this post, I will explain the transformer architecture and its implementation at the code level. I referred to a scratch implementation for the PyTorch code!

The authors of the paper all left Google and founded their own companies, except for Lukasz Kaiser, who joined OpenAI. Five out of the 7 companies have become unicorns, with a combined valuation exceeding $17 billion. It's quite impressive.
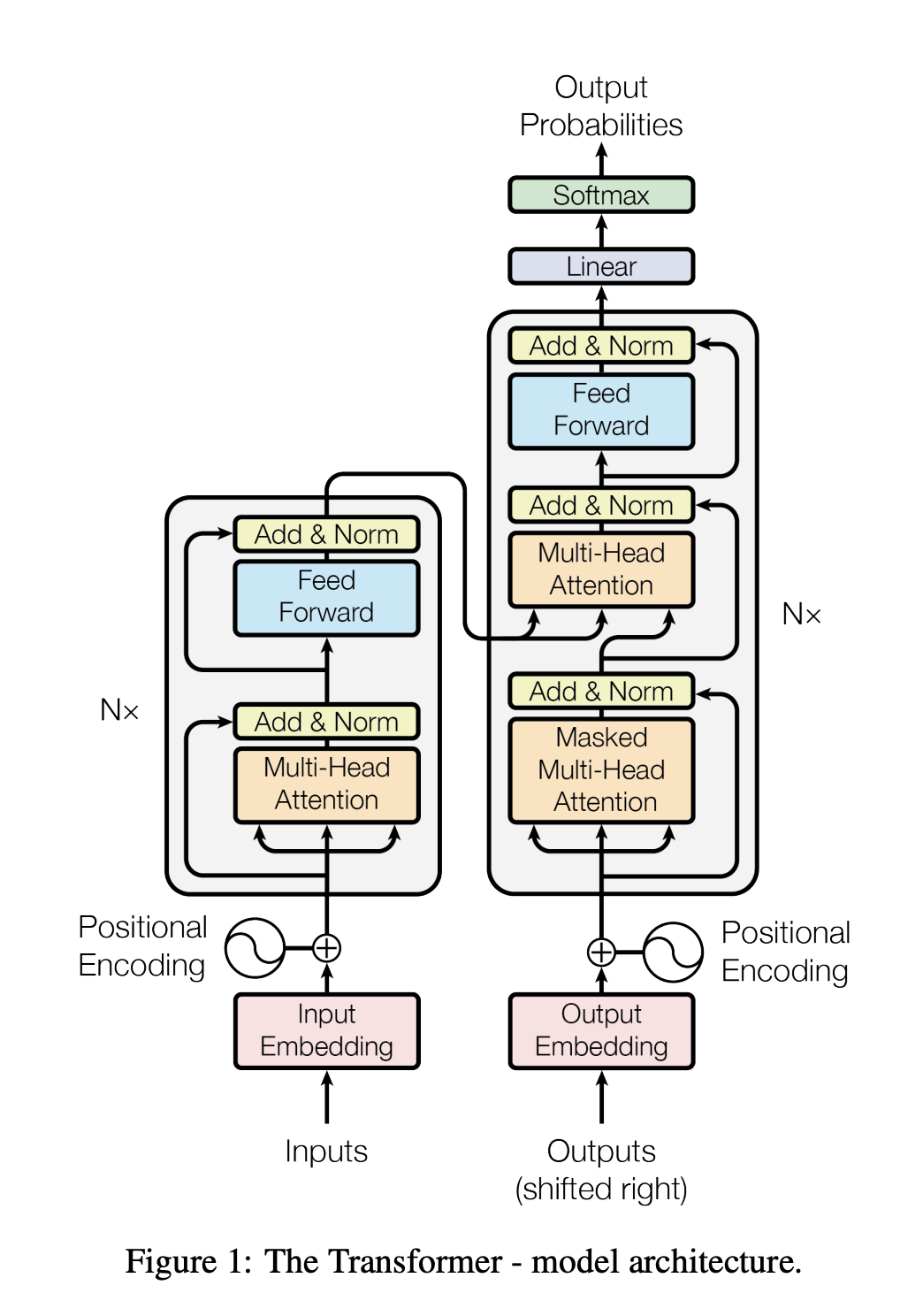
This is Figure 1 from the paper. It illustrates the overall architecture of the Transformer.
They designed the operation, called Scaled Dot-Product Attention, which calculates the attention scores between query and key vectors to reflect the context information between the tokens.
They represented the formula like this.
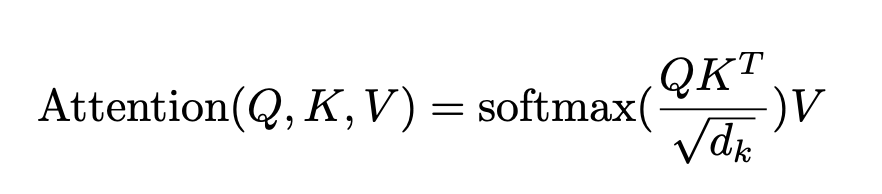
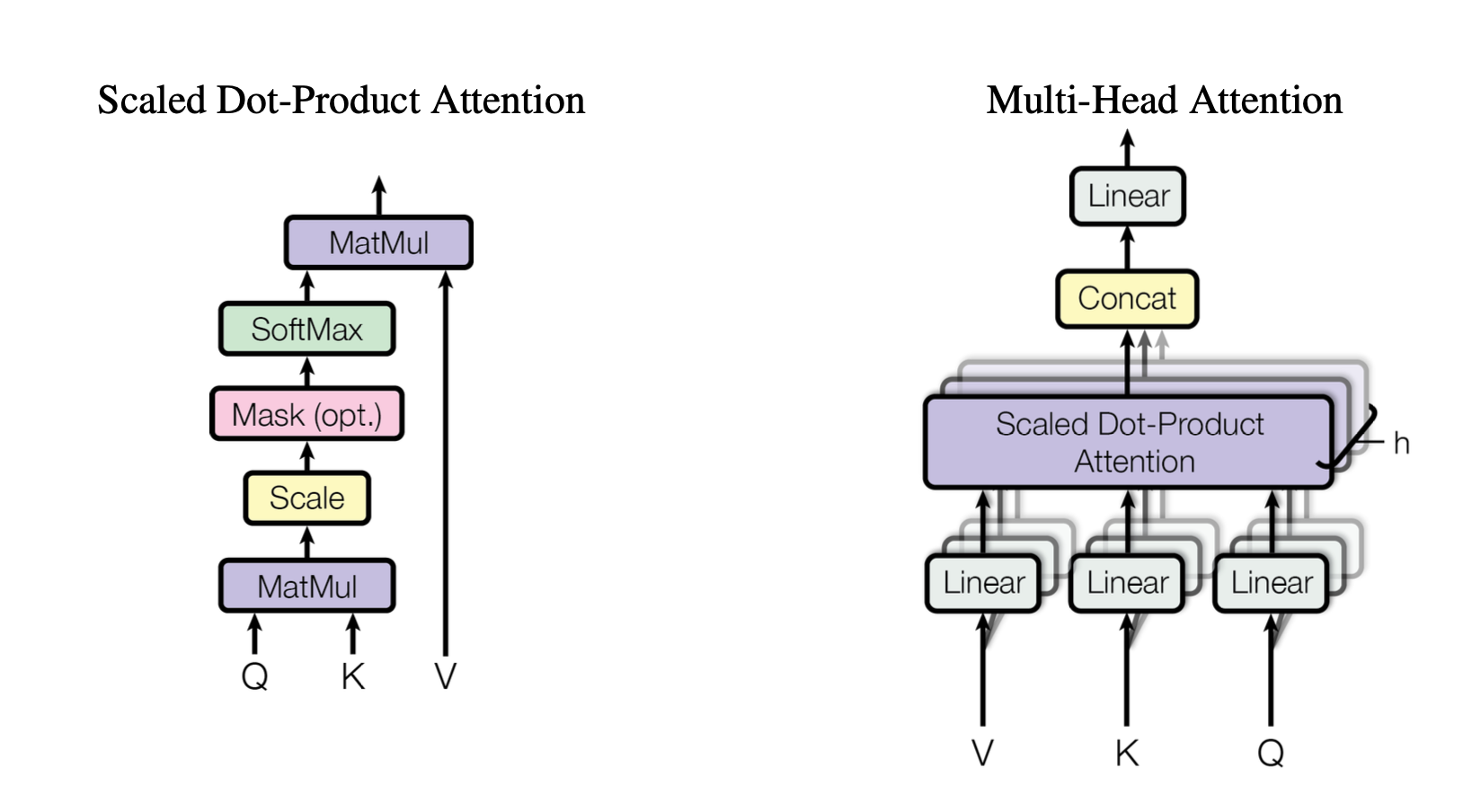
How can we implement Scaled Dot-Product Attention in PyTorch? Let's start from scratch.
class ScaledDotProductAttention(nn.Module):
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
# q = [batch_size, n_head, len_q, d_k]
# k = [batch_size, n_head, len_k, d_k]
# v = [batch_size, n_head, len_k, d_v]
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attnThe original method uses the square root of d_model for normalization, but this approach uses a learnable temperature parameter during training. A higher temperature value results in a more uniform attention distribution.
attn has a shape [batch_size, n_head, len_q, len_k], which represents the attention scores between query and key vectors. For example, a[:,:,1,2] is the attention score between the first query vector and the second key vector.
A mask is applied to ignore padding tokens in the sequence for efficiency and to ensure that self-attention in the decoder does not reference future tokens.
The output has a shape of [batch_size, n_head, len_q, d_v]
This is just one module used in the Multi-Head attention mechanism.
class MultiHeadAttention(nn.Module):
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
# q = [batch_size, len_q, d_model]
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q # enc_input
# Separate different heads: [batch, len, n_head, d] (d_model / n_head = d_k)
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: [batch, len, n_head, d]
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1)
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
# LayerNorm(x + Sublayer(x))
q += residual
q = self.layer_norm(q)
return q, attnWait, what is the layer function? And what does fc mean? I recommend reading pytorch layer (this is a Korean blog), which provides a concise explanation.
The Multi-Head Attention mechanism takes parameters q, k, and v. In practice, all of them are derived from the same input x. This is why the residual connection is applied to q.
After performing Scaled Dot-Product attention and applying transpose(1, 2).contiguous().view(sz_b, len_q, -1), q has a shape of [sz_batch, len_q, n_head * d_v]. In the original architecture, d_v = d_k, but when d_v != d_k, it ensures that the output and input dimensions of the fc layer remain consistent.
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid)
self.w_2 = nn.Linear(d_hid, d_in)
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return xThis is Feed Forward Network. It is a simple linear transformation followed by a ReLU activation function and a dropout layer.
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super().__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None):
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask)
enc_output = self.pos_ffn(enc_output)
return enc_output, enc_slf_attn
class DecoderLayer(nn.Module):
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super().__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, dec_input, enc_output, self_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=self_attn_mask
)
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attnIn fact, the Encoder and Decoder are straightforward implementations of their respective layers. It's more an algorithmic problem - determining where to provide the input and how to obtain the output. Therefore, I'll skip the following code snippets. If you want to a deeper dive into the Transformer code, please refer to the scratch.
reference
- Attention is all you need: https://arxiv.org/abs/1706.03762
- transformer code: https://github.com/jadore801120/attention-is-all-you-need-pytorch