CLIP
2025-07-14
7월부터 DSBA 연구실에서 인턴을 하는 중입니다. 저와 같은 AI 무지랭이를 위해 감사하게도 사전학습이란 제도가 있습니다. 연구실의 관심 분야인 CV(Computer Vision), NLP(Natural Language Process), TS(Time Series)에 대해 각각 분야 별 논문들을 읽고, Notion에 정리한 뒤, 기존 연구원 분들 앞에서 읽은 내용에 대해 1) 어떻게 읽었는지, 2) 느낀 점은 무엇인지, 3) 읽은 뒤 궁금한 점은 무엇인지 들을 이야기하는 시스템입니다.
이와 관련하여 인턴 동안 Notion에 적었던 내용을 블로그에 옮기려 합니다. 이후 마지막 단락에서 짧은 개인적인 생각을 남겨보겠습니다.
*This is a same content with the above paragraph.
I've been interning at the DSBA lab at SNU since July. Thankfully, there is a preparatory program for freshman and intern who have little to no background in AI research. The program focuses on DSBA's main research interests: Computer Vision (CV), Natural Language Process (NLP), and Time Series (TS). As part of the program, I read papers in each field, summarize them in Notion, and then present to the current researchers about 1) how I approached the paper, 2) what I thought or felt about it, and 3) any questions that came up during my reading.
I'm planning to transfer the contents I wrote in Notion to my blog. At the end of each post, I'll also share some brief personal thoughts.
다음 구분 선까지 Notion 내용입니다.
1. Introduction
- The research area covered by the paper
- Vision model training with natural language
- Multi-modal models
- Natural language supervision and weakly-supervised training
- Transfer learning
- Zero-shot and few-shot transfer task capabilities
- Limitations of previous studies in this task
- Existing datasets for training vision models are limited in size, as they are labeled data.
- Existing models lack the ability to perform zero-shot transfer on various downstream tasks.
- Contributions
- Presenting a large-scale dataset and a pre-training methodology based on weakly-supervised training)
- (The paper states that) Could scalable pre-training methods which learn directly from web text result in a similar breakthrough in computer vision?
- Focusing on the capability to solve task using zero-shot transfer
- While existing models focus on learning better representations, CLIP is designed to directly solve tasks (e.g., shifting from 'how to represent a cat image well' to 'how to classify a cat image well')
- (The paper states that) While much research in the field of unsupervised learning focuses on the representation learning capabilities of machine learning systems, we motivate studying zero-shot transfer as a way of measuring the task-learning capabilities of machine learning systems.
2. Related Work
- Improved deep metric learning with multi-class n-pair loss objective, Advances in neural information processing systems 2016
- The N-pair loss was intoduced to efficiently learn representations by considering samples from multiple classes at once.
- CLIP employed the N-pair contrastive loss
- Learning Visual Features from Large Weakly Supervised Data, ECCV 2016
- A CNN-based model was trained using a large-scale weakly-supervised dataset.
- The model could achieve generalization even when the labels were weak (contaminated or incomplete), as long as there was enough data.
- Learning Visual N-grams from Web Data, IEEE 2017
- The model is trained to associate N-grams from images and text
- It models concepts not as single word, but as phrases or even entire sentences.
- VirTex, ICMLM, ConVIRT _ These models also use a text-image architeccture, which served as an inspiration for CLIP.
3. Proposed Methodology
Main Idea & Contribution
- Architecture
Text encoder: Transformer - 63M parameter, 12 layer, 512 wide model with 8 heads
Image encoder
| Base style | EfficientNet style | ||
|---|---|---|---|
| ResNe | ResNet-50, ResNet-101 | RN50x4, RN50x16, RN50x64 |
| Base | Large | |
|---|---|---|
| ViT | 16, 32 | 14, 14@336px |
CLIP model used ViT-L/14@336px, which showed the best performance)
For the largest model, RN50x64 was trained on 592 V100 GPUs for 18 days, while ViT-L/14 was trained on 256 V100 GPUs for 12 days.
An implementaion of the code. (https://github.com/openai/CLIP)
Skip an unnecassary code.
class CLIP(nn.Module):
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
def encode_image(self, image):
return self.visual(image.type(self.dtype))
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_textYou can find clean and well-organized from-scratch implementations of ResNet, ViT, and Transformer in the CLIP/clip/model.py file of the repository. It's a great reference if you want to see how these models are implemented from the ground up.
- Natural Language Supervision
(The paper states that) It’s much easier to scale natural language supervision compared to standard crowd-sourced labeling for image classification. (…ellipsis) methods which work on natural language can learn passively from the supervision contained in the vast amount of text on the internet.
OpenAI, known for gathering massive datasets for GPT training, demonstrates impressive web crawling capabilities.
-
They set up 500K queries and crawled (image, text) pairs for each.
-
For each query, they collected up to 20,000 pairs, ensuring balanced class distribution.
-
In total, they gathered 400 million paris--comparable in total word count to the WebText dataset used for GPT-2 training.
-
Training Method
(The paper states that) Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N ×N possible (image, text) pairings across a batch actually occurred.
This results in an N x N matrix of image and text pairs, where only the diagonal elements are considered positive examples, and all others are treated as negatives during training.
Q) How does the model handle false negatives?
A) As long as the dataset is sufficiently large, even if some data is low-quality, it does not significantly hinder training. (This demonstrates the strength of weak supervision.)
A key question to verify through experiments: Will zero-shot transfer performance truly improve during pre-training, as it did with GPT?
4. Expreiments and Results
This paper is quite lengthy, with most of its content dedicated to experimental design, results, and their significance. Therefore, I will go through each experiment one by one.
1) vs Visual N-Grams
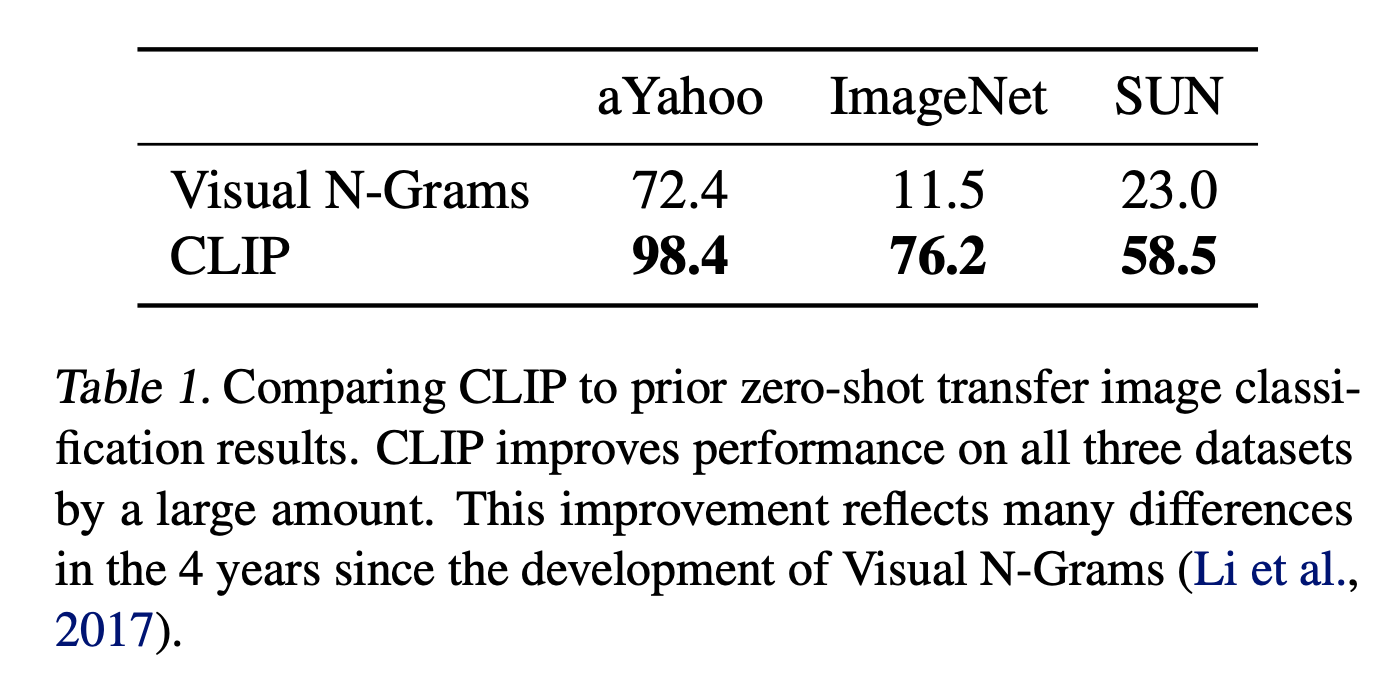
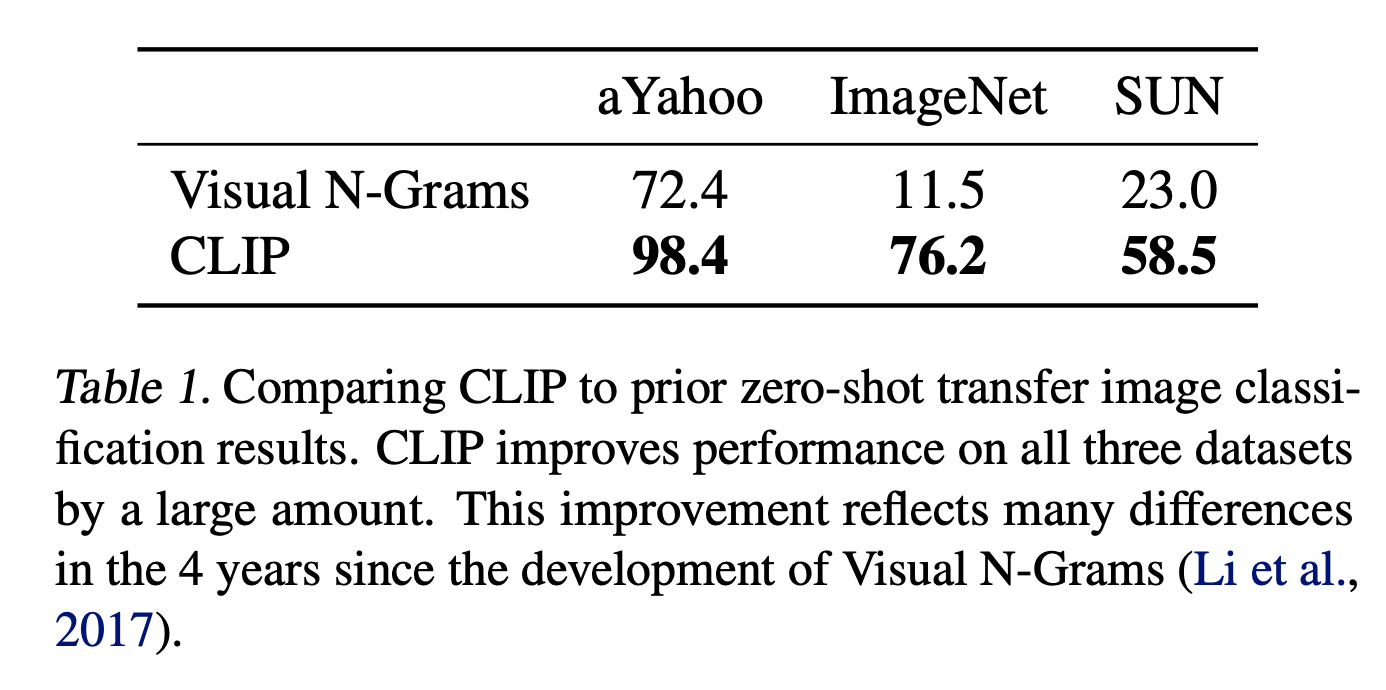 As mentioned in the paper, Visual N-Grams and CLIP are not directly comparable models due to their architecture, dataset what they train, and so on. However, this table demonstrates just how much zero-shot performance has improved.
As mentioned in the paper, Visual N-Grams and CLIP are not directly comparable models due to their architecture, dataset what they train, and so on. However, this table demonstrates just how much zero-shot performance has improved.
2) Prompt Engineering for Image Encoding
During pre-training, the text in CLIP's dataset consist of phrases or sentences (captions) that describe the image. However, in some evaluation datasets, only the class label is provided. In such cases, even simple prompt engineering can lead to significant performance improvements.
- Basic template: "A photo of a label" -> 1.3% improvement on ImageNet dataset
- Oxford-IIIT Pets: "A photo of a lable, a type of pet"
- OCR: Add quotes around characters or numbers, e.g., 1, a -> "1", "a"
Beyond these, various context prompts led to a total improvement of 3.5% on ImageNet. (The promptes used are summarized in CLIP/data/prompts.md on GitHub.)
Examples of prompt.
templates = [
'a photo of a {}.',
'a blurry photo of a {}.',
'a black and white photo of a {}.',
'a low contrast photo of a {}.',
'a high contrast photo of a {}.',
'a bad photo of a {}.',
'a good photo of a {}.',
'a photo of a small {}.',
'a photo of a big {}.',
'a photo of the {}.',
'a blurry photo of the {}.',
'a black and white photo of the {}.',
'a low contrast photo of the {}.',
'a high contrast photo of the {}.',
'a bad photo of the {}.',
'a good photo of the {}.',
'a photo of the small {}.',
'a photo of the big {}.',
]The prompts are ensembeld by pooling the embeddings obtained from each individual prompt input.
Q) Does this increase inference time?
A) The text encoder computes embeddings for the ground-truth labels in advance, and during inference, only the similarity with the image embedding needs to be calculated. Therefore, as long as the cached values are used, increasing the number of prompt templates does not proportionally increase inference cost!
3) Zero-Shot CLIP Performance
vs fully Supervised models
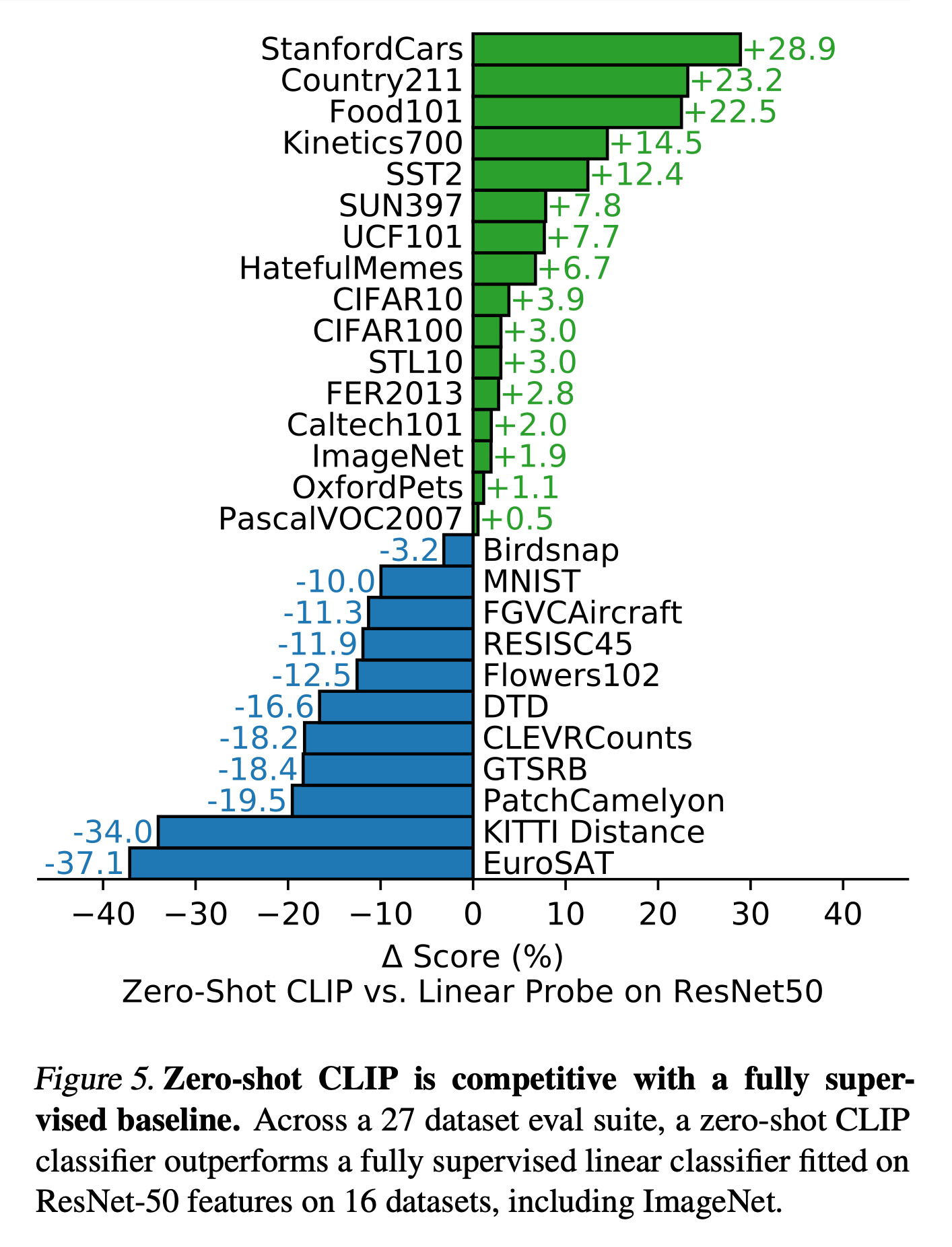
On quite a few datasets, CLUP outperforms the fully supervised baselines.
Which datasets showed poor performance?
→ (The paper states that) we see that zero-shot CLIP is quite weak on several specialized, complex, or abstract tasks such as satellite image classification (EuroSAT and RESISC45), lymph node tumor detection (PatchCamelyon), counting objects in synthetic scenes (CLEVRCounts), self-driving related tasks such as German traffic sign recognition (GTSRB), recognizing distance to the nearest car (KITTI Distance).
For highly specialized or complex image recognition tasks, transfer performance tends to be poor.
However, these cases likely involve classes that were ralely, if ever, encountered during pre-training. Considering the performance of non-expert humans on such zero-shot tasks, this result is understandable.
vs Few-shot models
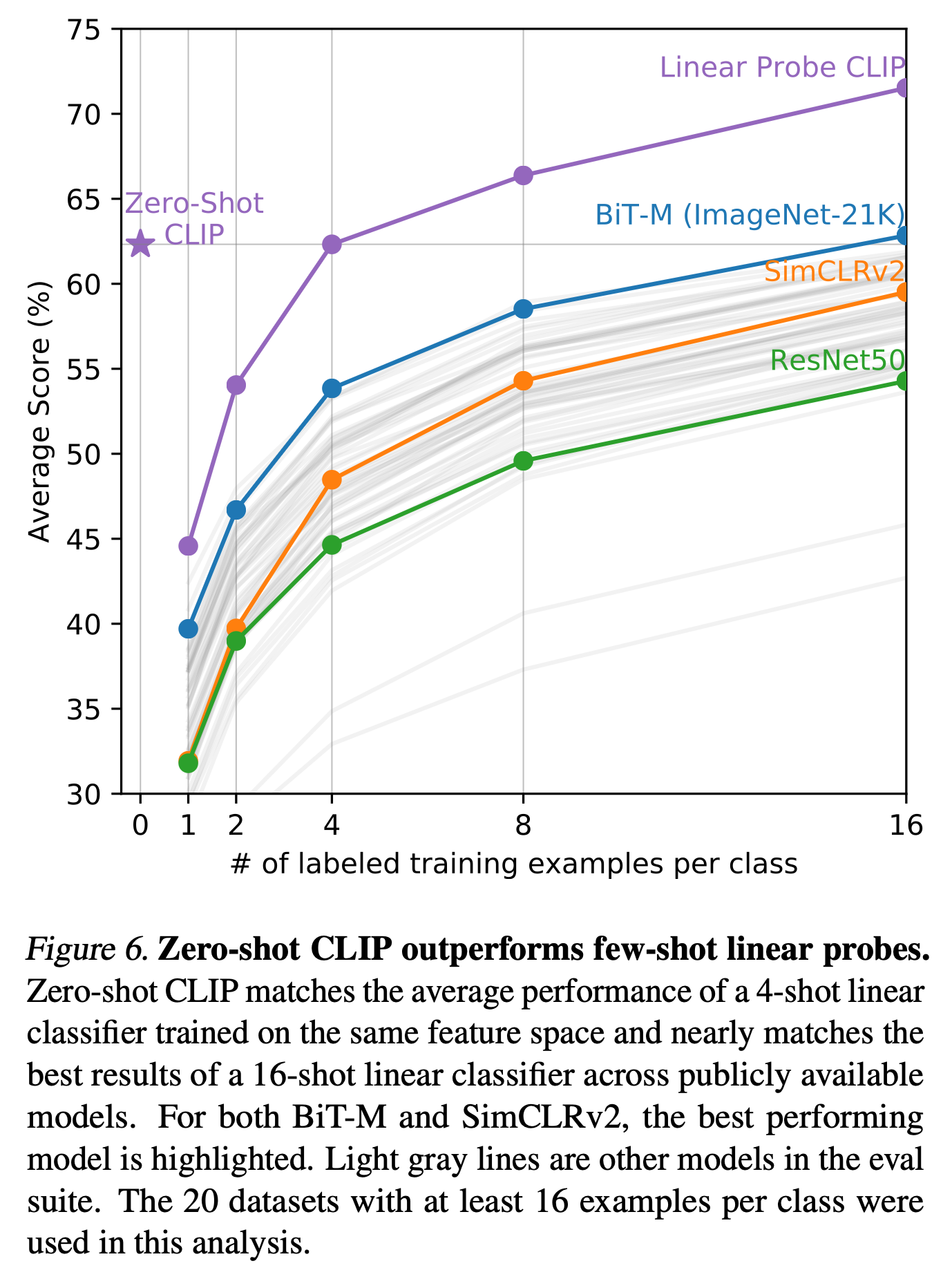 Linear Probe CLIP is evaluated after being trained with Logistic Regression.
Linear Probe CLIP is evaluated after being trained with Logistic Regression.
What's remarkable is that, up to 4-shot, CLIP's zero-shot performance remains higher.
→ (The paper states that) Context-less example-based learning has the drawback that many different hypotheses can be consistent with the data, especially in the one-shot case.
Q) why it does?
A)
- Images exhibit much higher variance compared to text. Even within the same class, factors like lighting, angle, background, resolution, style, and noise can make images look completely different.
- In contrast, text is structured and conveys meaning clearly.
-> The difference in clarity between presenting a cat as a photo versus as a word 'cat'.
To sufficiently learn the visual features of images, a large number of few-shot samples is required.
Q) Does this mean that as image resolution increases, even more few-shot samples are needed?
A) (by GPT in Korean)
네, 맞습니다!
**이미지의 픽셀(해상도)이 늘어날수록, few-shot 학습에서 더 많은 샘플이 필요해지는 경향이 커집니다.**
---
## 이유를 자세히 설명하면
### 1. **고차원 공간의 일반화 어려움**
- 이미지의 해상도가 높아질수록, 각 샘플이 가지는 정보(특징)도 훨씬 더 많아집니다.
- 예를 들어, 32×32 픽셀 이미지는 1,024차원, 224×224 픽셀 이미지는 50,176차원입니다.
- 고차원 공간에서는 데이터가 희박(sparse)해지고,
클래스 경계를 잘 잡으려면 더 많은 예시가 필요합니다.
### 2. **시각적 다양성 증가**
- 해상도가 높아지면,
같은 클래스 내에서도 더 다양한 세부적인 특징(무늬, 질감, 배경 등)이 나타날 수 있습니다.
- 모델이 이런 세부적인 차이를 일반화하려면 더 많은 샘플이 필요합니다.
### 3. **오버피팅 위험 증가**
- 샘플 수가 적은데 픽셀(특징) 수가 많으면,
모델이 소수 샘플의 세부적인 특징에 과도하게 적합(overfit)될 위험이 커집니다.
- 이를 방지하려면 더 많은 샘플로 클래스의 전체적인 특징을 학습해야 합니다.
---
## 실제로 어떻게 나타나는가?
- **해상도가 높을수록**
- 같은 클래스의 다양한 모습(포즈, 배경, 조명 등)을 더 많이 포착할 수 있음
- 모델이 이런 다양성을 학습하려면 더 많은 예시가 필요함
- **few-shot 학습에서**
- 저해상도 이미지(예: MNIST, CIFAR-10)는 1~5장만으로도 어느 정도 일반화 가능
- 고해상도 이미지(예: ImageNet, 의료 영상 등)는 10장 이상, 때로는 수십~수백 장이 필요할 수 있음
---
## 결론
- **이미지의 픽셀(해상도)이 늘어날수록, few-shot 학습에서 더 많은 샘플이 필요해지는 경향이 커진다**는 것이 맞습니다.
- 이는 고차원 데이터의 일반화 어려움, 시각적 다양성, 오버피팅 위험 등 때문입니다.the # of samples to deal with zero-shot model
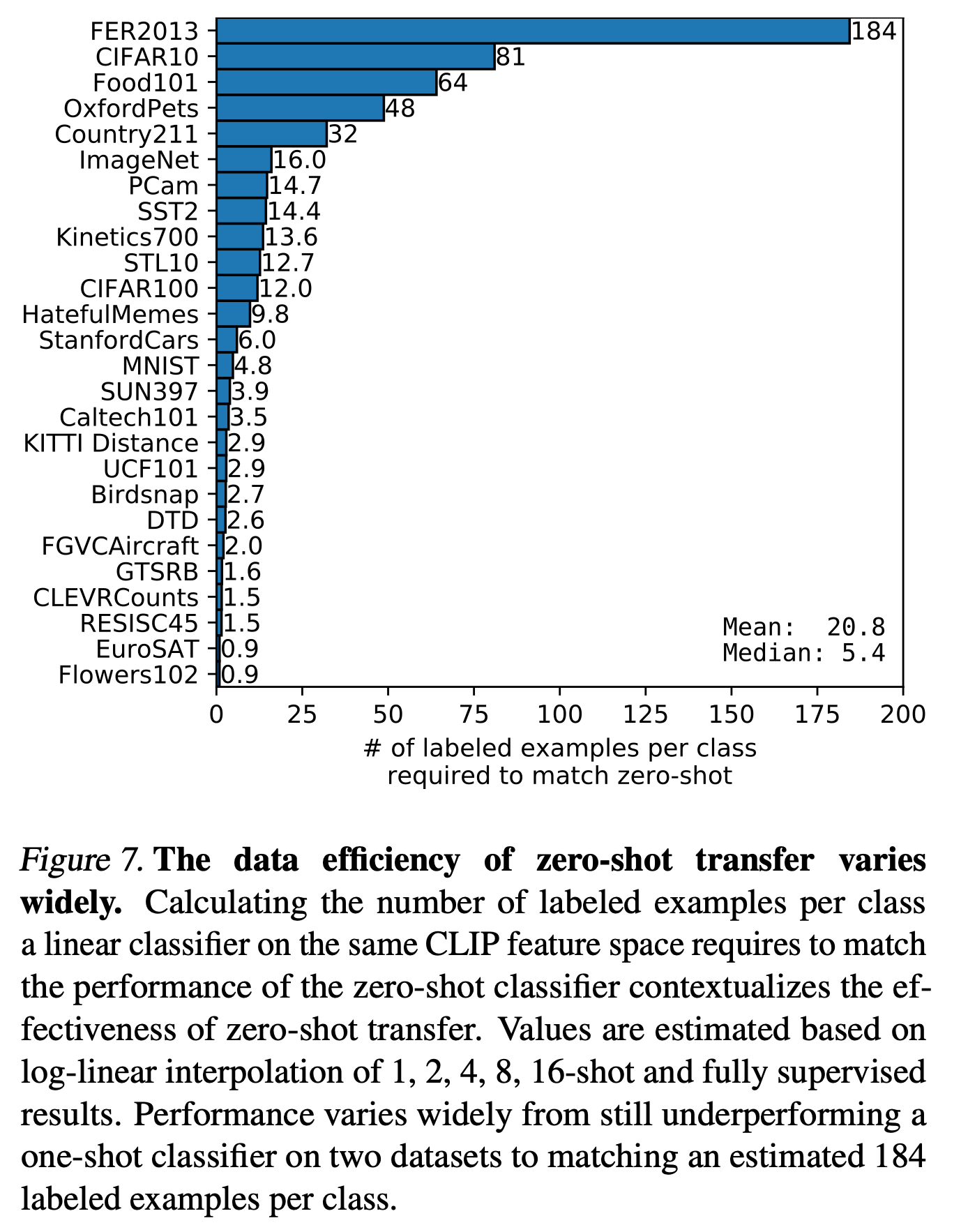
The number of few-shot samples required to match zero-shot performance for each dataset.
Let's take a closer look at the top four datasets:
- FER2013: Facial expression recognition -> It is difficult to learn consistent class representations due to the different ways people express emotions.
- CIFAR10: Low resolution and high intra-class variation.
- OxfordPets: Likely struggled with distinguishing between similar breeds.
- Food101: Even the same dish can look completely different depending on the recipe or the angle of the photo.
That said, I haven't examined each dataset in detail--these are just general observations based on their characteristics.
If a dataset has a large number of features that need to be captured within a class (as in FER2013), or contains a lot of background information unrelated to the class (as in Food101), few-shot learning becomes more challenging.
A theoretical limit performance and the real performances
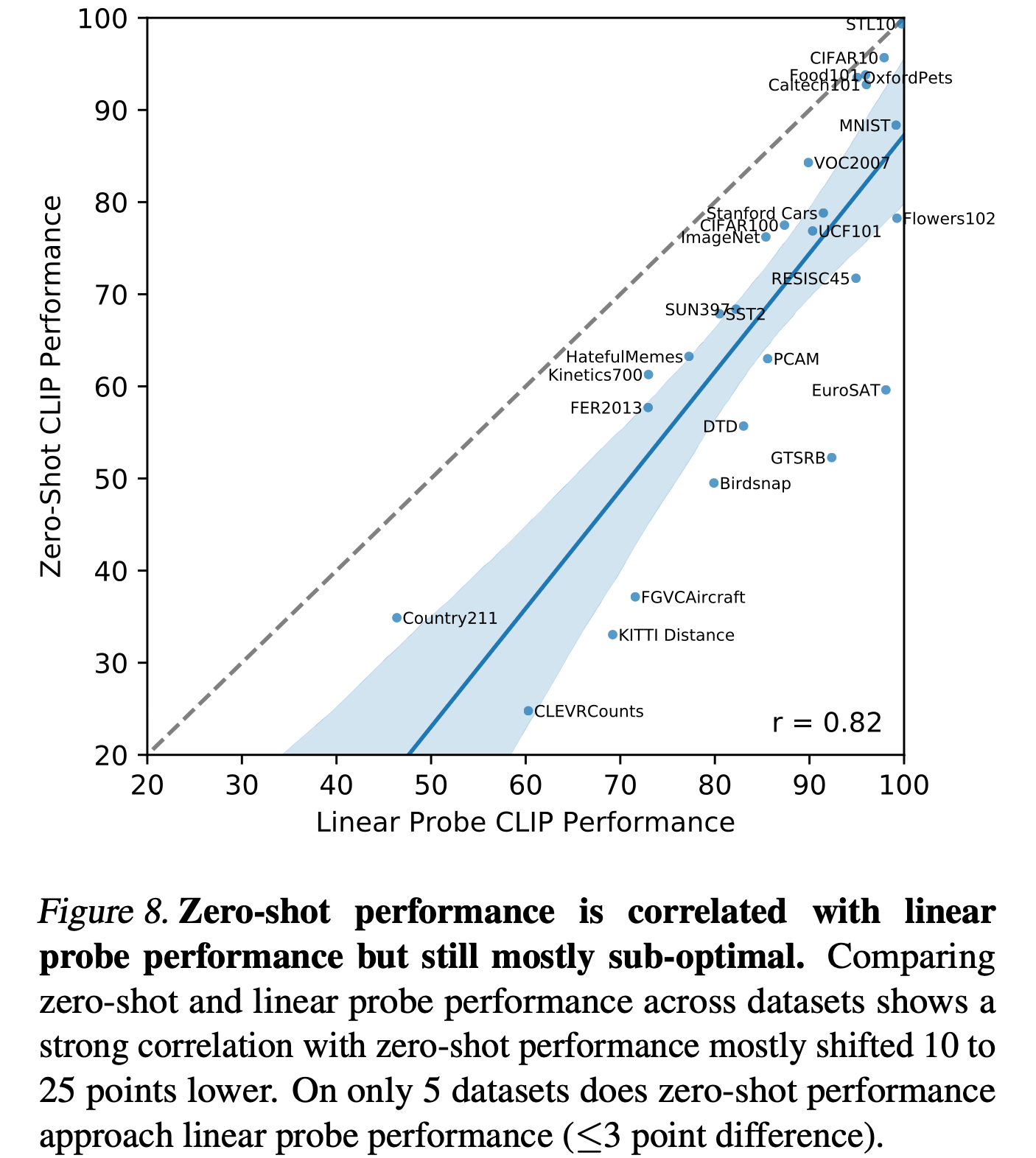 A comparison between theoretical performance and zero-shot results
A comparison between theoretical performance and zero-shot results
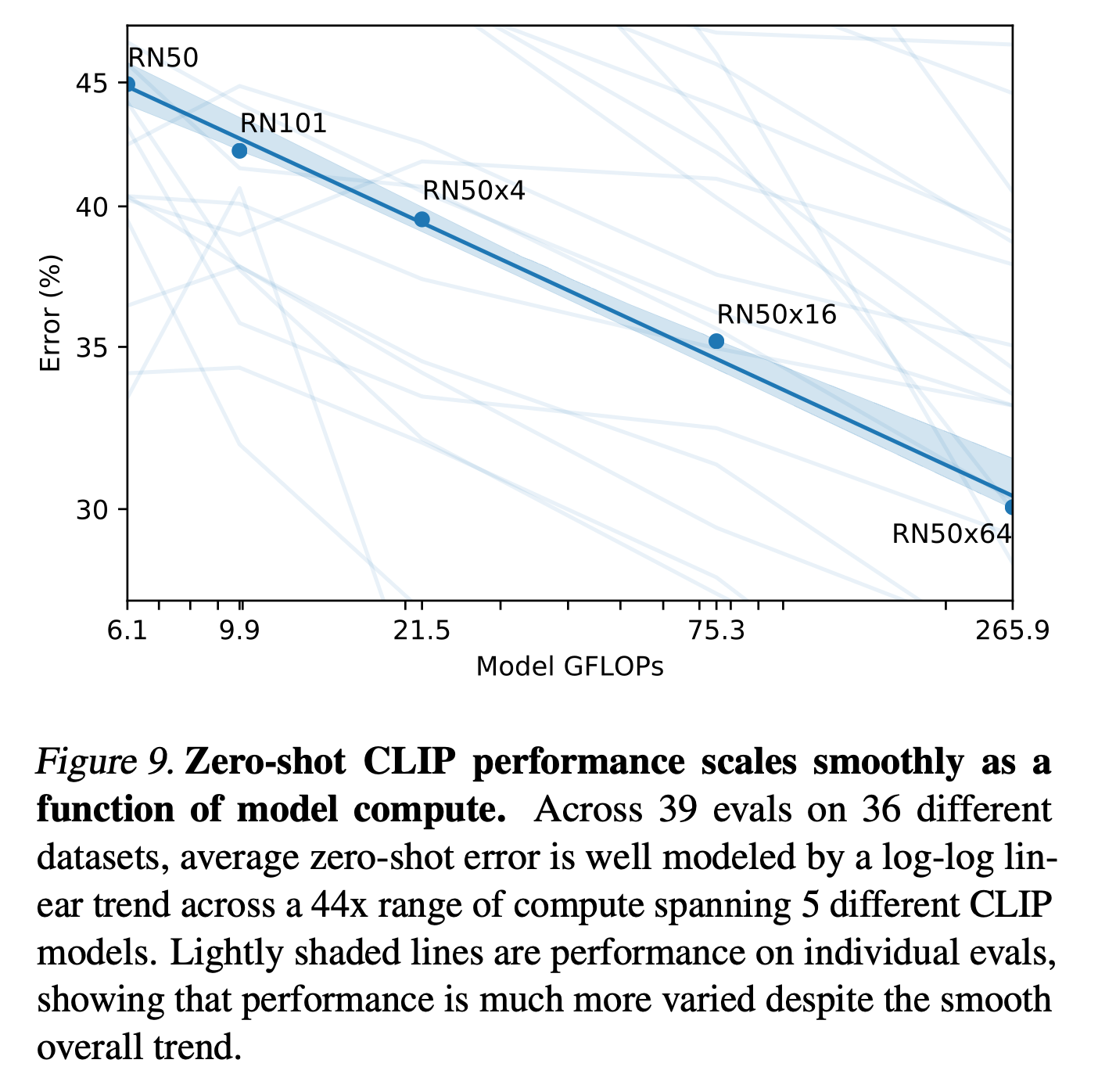 Comparison of model size and performance -- performance steadily increases, suggesting that larger models can achieve even better results.
Comparison of model size and performance -- performance steadily increases, suggesting that larger models can achieve even better results.
4) Representation Learning
Although the authors emphasize task learning capability over representation learning capability, they still evaluate the modles using conventional methods.
Experimental setup:
- The projection to the classification space is removed from each model
- scikit-learn's L-BFGS implementation is used
- The most appropriate metric for each dataset is chosen for evalution (see the images below and Appendix A in the papar for details)
Dataset and meta-information
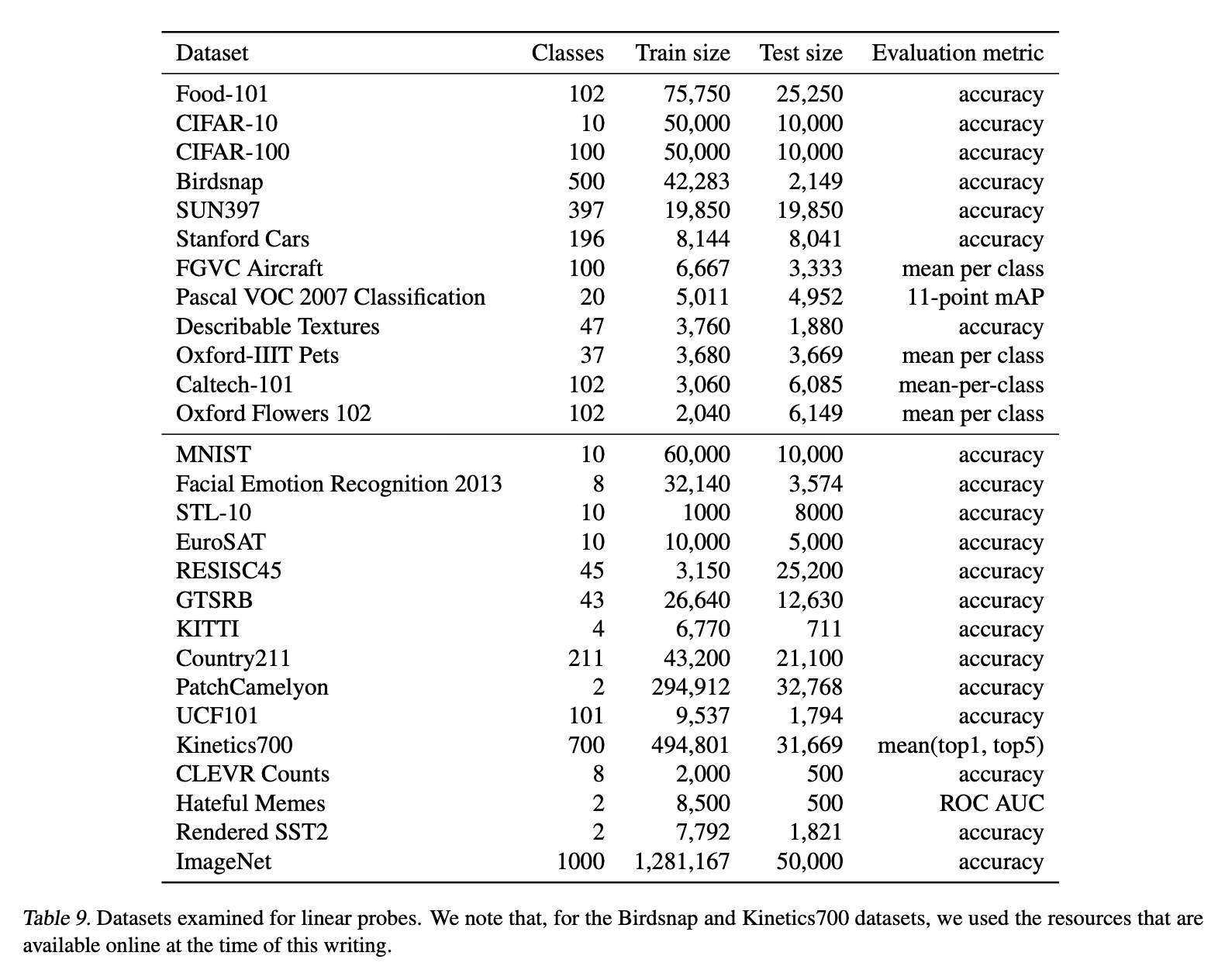

Visualization of the results:
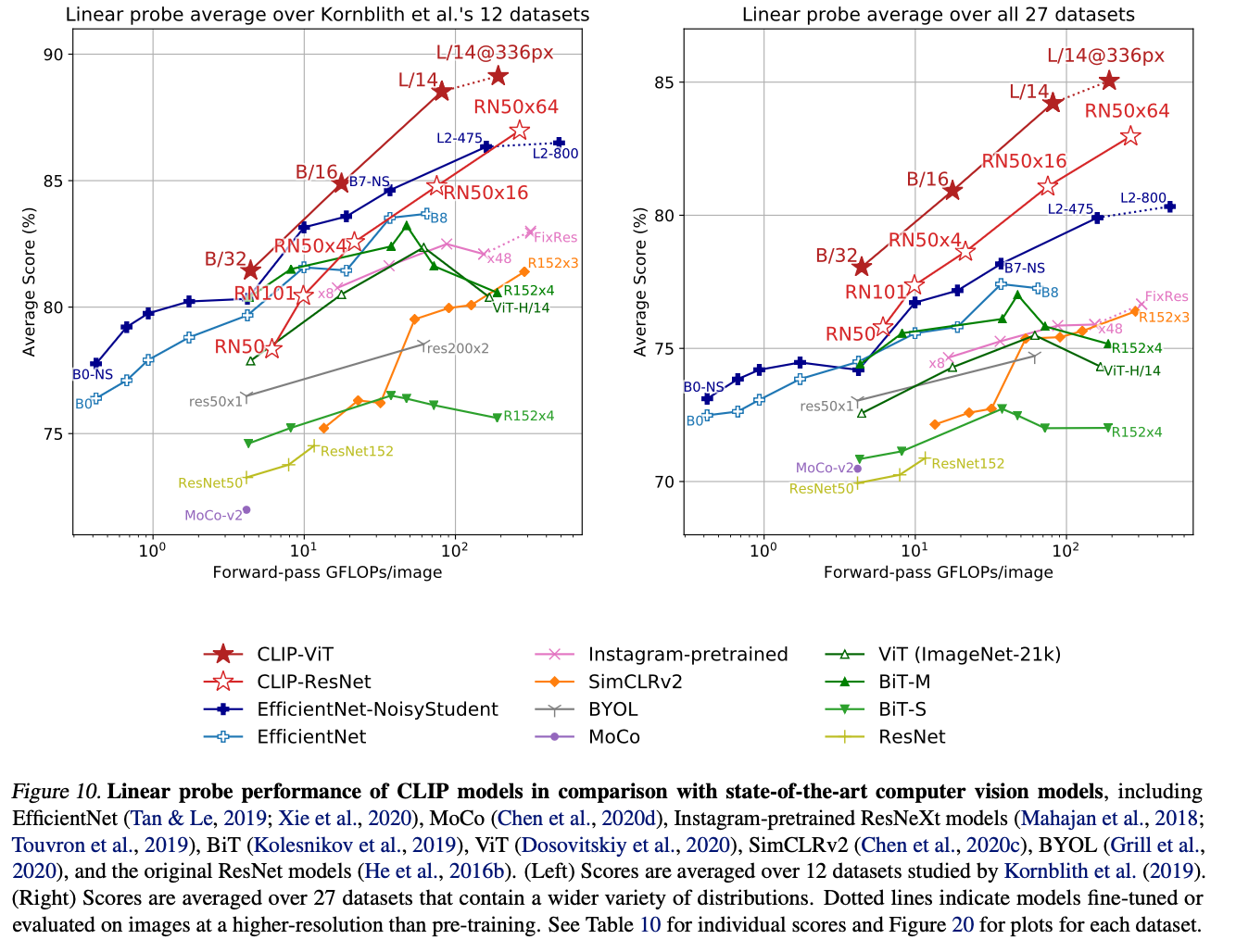
The large-parameter CLIP model demonstrates excellent embedding capabilities!
Q) Is linear probing a good indicaotr of embedding quality? A) If an embedding achieves strong performance with just a simple linear layer, it suggests that the embedding captures a wide range of visual and abstract features across images. Rather than being tailored to specific classes, it provieds a general-purpose representation. In other words, the model excels at extracting features for a variety of classes within images--indicating high-quality embedding representations!
5) Robustness to Natural Distribution Shift
This section presents experiments on transfer capability, which has been a recurring theme since the introduction.
The paper describes two types of robustness.
- Relative Robustness: it captures any improvement in out-of-distribution accuracy.
- Effective Robustness: it measures improvements in accuracy under distribution shift above what is predicted by the documented relationship between in-distribution and out-of-distribution accuracy.
Of course, for a model to be considered robust, both types of robustness should be high.
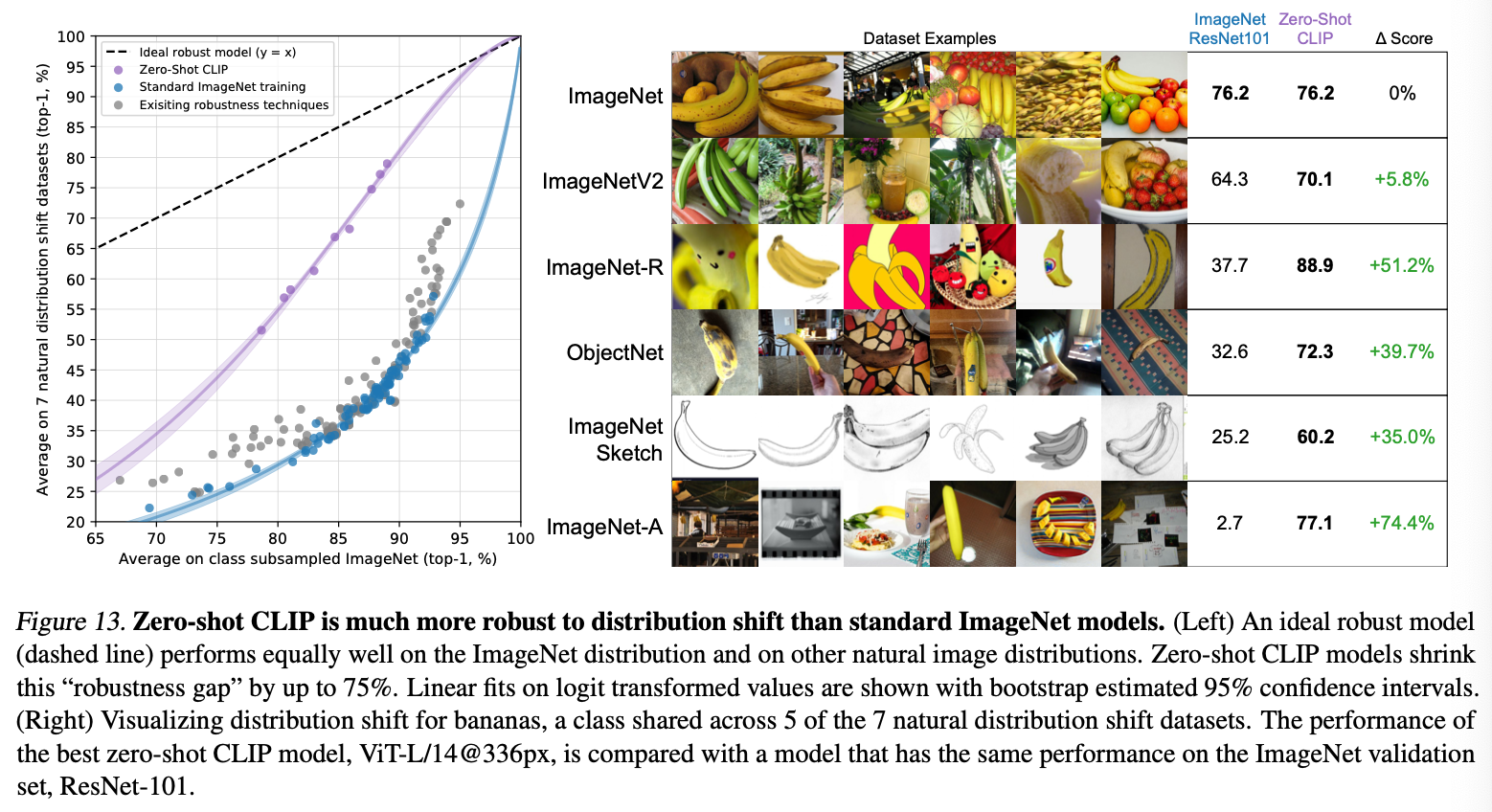 CLIP demonstrates even higher performance on different distributions. For example, on ImageNet-R, while performance of ImageNet-trained ResNet101 drops by about 40%, CLIP's performance actually inreases by 12%. This highlights how powerful it is to understand image structure through natural language--a precedent already set by GPT.
CLIP demonstrates even higher performance on different distributions. For example, on ImageNet-R, while performance of ImageNet-trained ResNet101 drops by about 40%, CLIP's performance actually inreases by 12%. This highlights how powerful it is to understand image structure through natural language--a precedent already set by GPT.
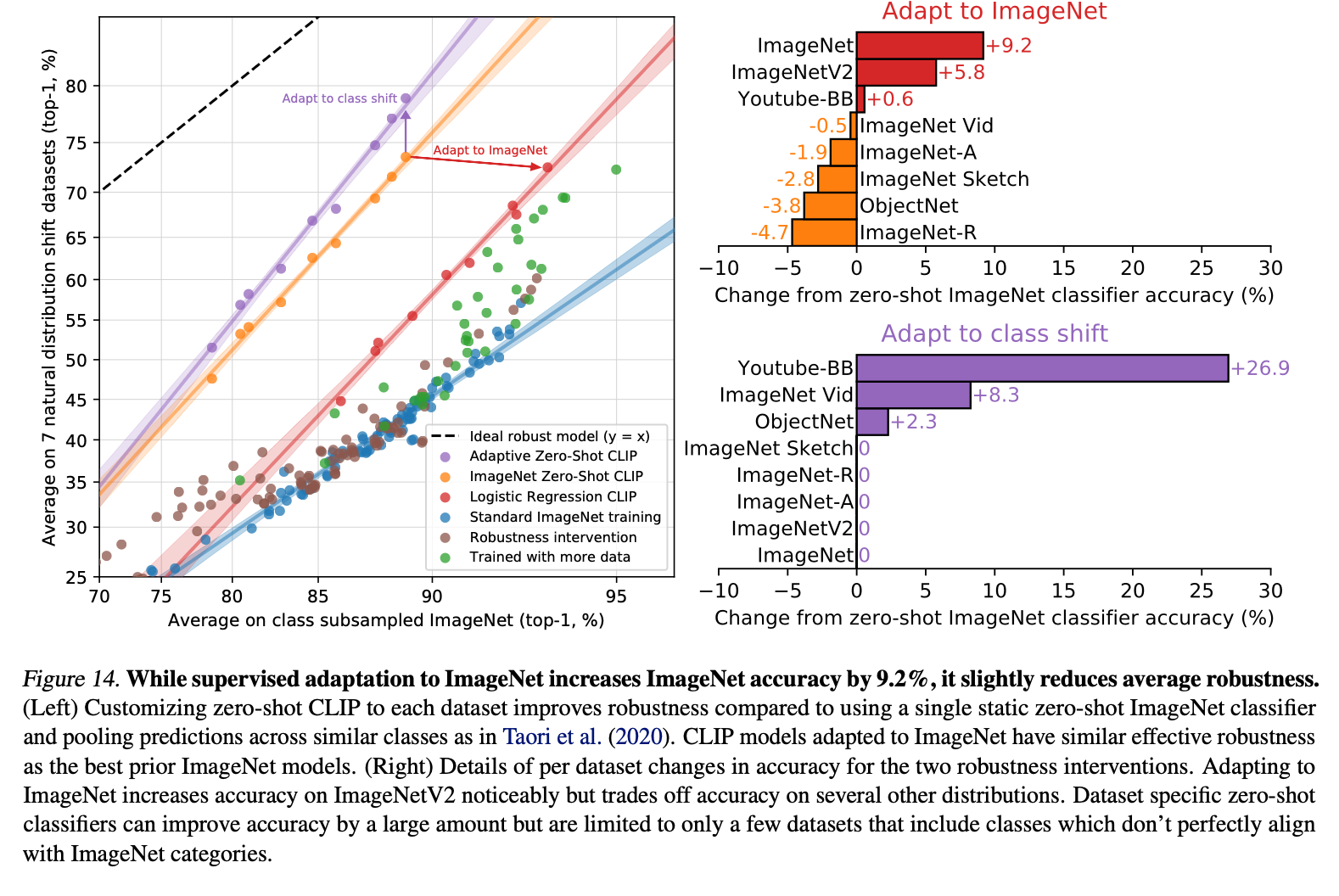 When trained specifically on ImageNet, robustness to other datsets decreases. However, if you align the class names for zero-shot CLIP, you can see significant performance improvements on certain datasets.
When trained specifically on ImageNet, robustness to other datsets decreases. However, if you align the class names for zero-shot CLIP, you can see significant performance improvements on certain datasets.
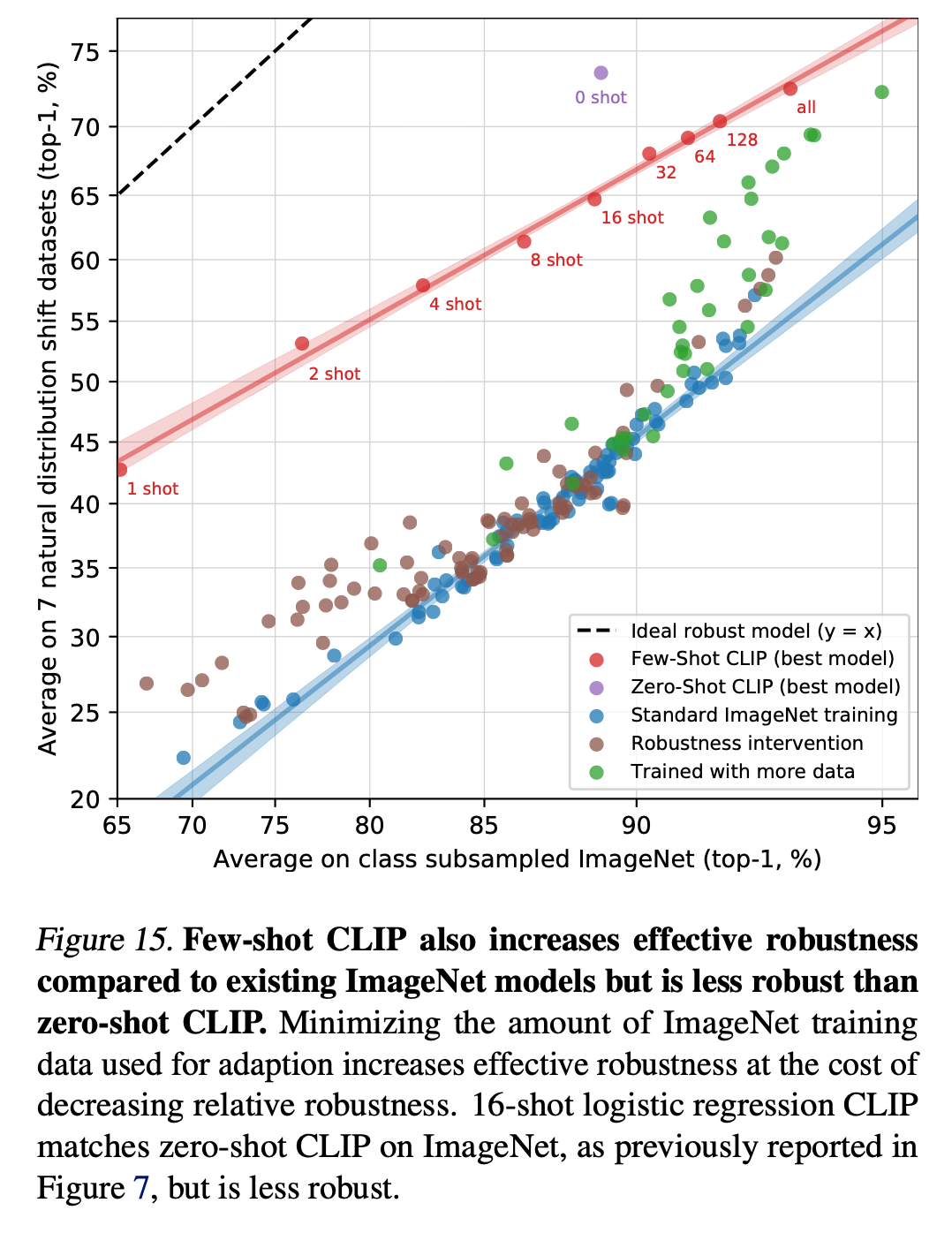 Zero-shot is much more robust than few-shot.
Zero-shot is much more robust than few-shot.
6) Comparison to Human Performance
CLIP is better
7) Data overlap
One of the challenges in evaluating pre-trained models is that evaluation datasets can sometimes overlap with training data. In this paper, the authors created an overlap detector to construct a clean subset, and fount that, except for a few datasets, the overlap was within acceptable limits. However, for more precise evaluation, it will be necessay to use evaluation datasets created after CLIP.
(The paper states that) Creating a new benchmark of tasks designed explicitly to evaluate broad zero-shot transfer capabilities, rather than re-using existing supervised datasets, would help address these issues.
8) Bias
Since the model is trained on large-scale internet data, it inevitably contains biases related to sexuality, race, and occupation.

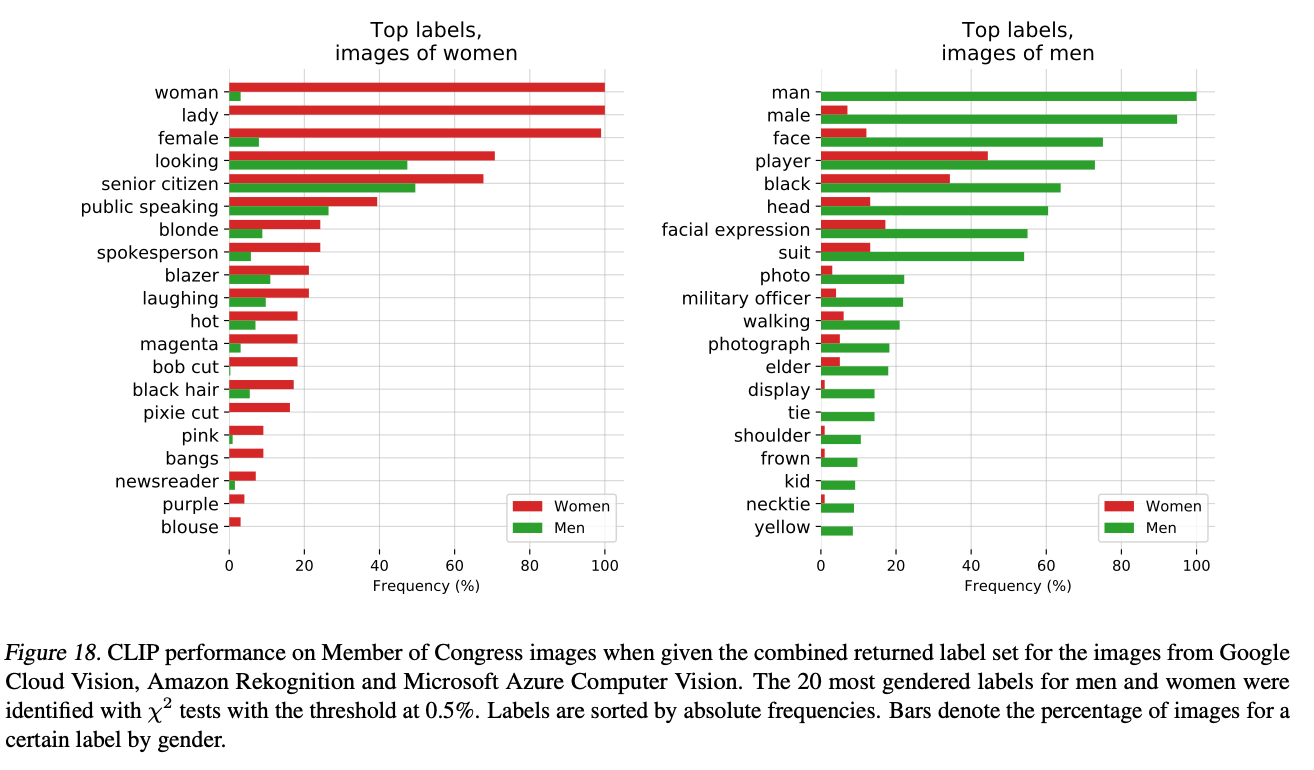
Just like with InstructionGPT, effective instruction tuning will be necessary.
5. Conclusion (Lessons learned)
Thanks to the abundance of insights gained from leveraging massive resources, I found this paper highly engaging despite its considerable length. Each experiment could practically be a research topic on its own.
On a personal note, I've also been reading papers in the speech-to-text domain. Similar to CLIP, Whisper, which is audio model made by OpenAI, presents a pre-trained model built on a natural supervision dataset and shares a variety of experimental results. Along with GPT-3, it's clear that OpenAI has laid the foundation for most of today's AI models.
What stood out in this paper was the clear focus on 'task learning capability' rather than just 'representation learning capability,' and the strong intention to build AI models that are meaningful in the real world.
Although OpenAI has since shifted to closed models, their ahcievements so far truly embody the spirit of "Open" AI. I was especially moved by the paragraph on the right side of page 25.
- We hope that this work motivates future research on the characterization of the capabilities, shortcomings, and biases of such models, and we are excited to engage with the research community on such questions.
정말 재미있게 읽었다. 꽤 긴 분량이라 처음에는 어떻게 읽나 싶었는데... 하나하나 살펴보는 재미가 있었고 금방 다 읽었다. 이 논문 하나만으로도 정말 배운 게 많았음.
실은 OpenAI가 단순히 ChatGPT로 유명한 줄 알았다만, 초창기에 추구했던 가치와 의미를 보니 정말 멋있는 걸 넘어서 애초에 현재 LLM 시대의 완전한 바탕인 셈이었다.