최근 읽은 논문들 간단 정리
2025-06-30
이래 저래 여러 논문과 블로그를 보는데... 끝이 없다. 그리고 논문 리뷰를 블로그에 열심히 작성하는 것도 뭔가 애매한 듯하고. 약간 개발 블로그처럼, 모두가 논문 리뷰를 하지만 거기에 본인만의 특색이 있는 글은 많지 않다. 심지어 어떤 글들은 인터넷에 있는 정보를 그대로 가져다 붙인 수준이기도 하고.
차라리 읽은 논문 중 얻은 인사이트를 가볍게 뽑아서 정리하는 게 훨씬 좋을 듯하다고 느꼈다. 어차피 요약이나 의의 등은 나보다 AI가 잘 해주니까. 그래서 그냥 최근에 읽은 것들에 대해 간단한 요약을 적고, 나름대로 영어 공부 겸 AI의 정리를 옮겨 적으며 다시금 되짚는 용도로 글을 써볼 생각!
Transformer-XL
XL means extra-large. Transformer-XL can handle a long context window. The main idea is similar to an RNN. It separates a long context into segments and uses the hidden state of each segment to retain information from previous segments.
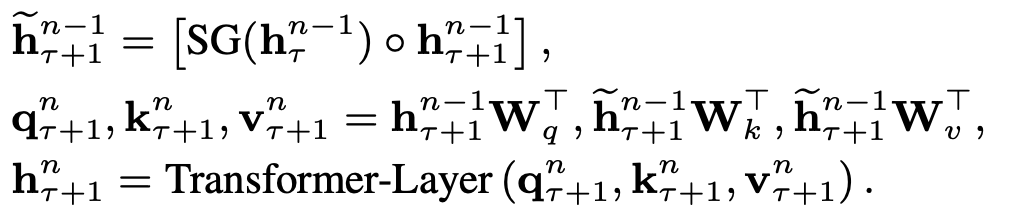
Therefore, it adopts a relative positional encoding.
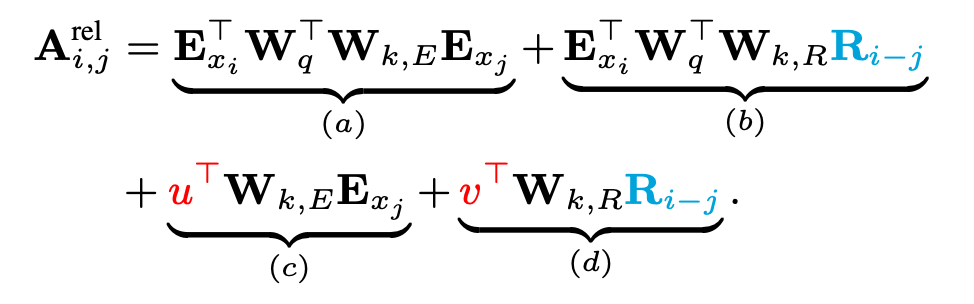
I didn't understand why the 3 terms are added to calculate the attention score. Here's an explanation of each term.
- Content score: Q * K^T - A simple attention score
- Position score: Q * R^T - An inner product of query and relative positional embedding
- Content bias = U * K^T
- Positional bias = V * R^T
- Bias terms adjust the important score. But... they're just bias terms to improve better performance.
Wav2Letter
Wav2letter is designed as a simple end-to-end system for speech recognition, directly converting a speech signal into a text transcription. A key feature is that its acoustic model is trained directly using letters (graphemes). This breaks away from the classical pipeline.
Architecture
- The system is built around a standard 1D convolutional neural network (ConvNet) for acoustic modeling.
- It uses striding convolutions instead of pooling layers to allow the network to perceive a larger context without increasing the number of parameters.
- The architecture for processing raw audio, as illustrated in the paper, involves a series of convolutional layers with specific kernel sizes and strides.
- The final layer of the convolutional network outputs a score for each letter in the predefined dictionary. The overall stride of the network is 320, generating a label every 20 milliseconds.
I don't discuss its architecture in detail, but just highlight the significance of this research.
- End-to-End architecture
- it directly converts a speech signal into a text transcription. This approach eliminates the need for intermediate phonetic transcriptions or forced alignment of phonemes. It generates a grapheme output directly.
- Introduction of automatic segmentation criterion (ASG)
- ASG is a simpler sequence criterion that trains models from sequence annotation without requiring alignment. It has few differences from CTC(Connected Temporal Classification). The most key point is a transition probability. It occurs between letters.
Wav2Vec
It applies unsupervised pre-training to learn robust representations from unlabeled audio, which are much easier to collect thana labeled data.
Architecture
- A multi-layer convolutional neural network (ConvNet) that takes raw audio as input.
- It consists of two main stacked networks. Encoder Network
fand Context Networkg. f embeds the raw audio signal into a low-frequency feature representationz. g takes multiple time-steps of the encoder's outputz_i...z_i-vand combines them into a single contextualized tensorc_i
Objective
- To distinguish a sample z_i+k that is k stpes in the future from distractor samples z tilda drawn from a proposal distribution p_n, by minimizing the contrastive loss for each step k = 1, ..., K
It is trained by discrimanating the correct sample among distractor samples.
VQ-Wav2Vec
VQ means vector quantizing. It makes a discrete data to use NLP.
wav2vec 2.0
It is the successor to wav2vec and VQ-wav2vec. wav2vec 2.0 uses self-supervised contrastive learning and discrete representations.
One thing I would like to discuss is the contrastive loss used in this paper.
A latent representation is fed to two layers: a context layer and a quantization layer.
c_t is the masked output of the context layer and q_t is the quantized output of the quantizing layer. The loss calculates the similarity between c_t and q_t so that context representation is close to q_t and far from the negative samples, q_t tilda.