VQ-VAE
2025-07-19
스크래치 구현(Original VAE와 같이 작성됨): GitHub
1. Introduction
- The research area covered by the paper
- Latent representation
- Vector Quantization
- Limitations of previous studies in this task
- Language and speech are inherently discrete in nature.
- This raises the question: since images can often be described using language, is it beneficial to represent images with discrete latent variables?
- Traditional VAEs suffer from posterior collapse problem.
- This occurs when the encoder becomes too closely aligned with the prior distribution, causing the latent variables to carry little or no meaningful information about the input.
- Contributions
- It shows a wide variety of applications such as speech and video generation.
- It doesn’t suffer from the posterior collapse problem.
2. Related Work
VAE
- it shows an architecture of VAE (inferring a variational latent)
3. Methodology
Main Idea
1. Discrete Latent variables
notations
- e: a embedding space
- K: the size of the discrete latent space (K-way categorical)
- D: the dimensionality of each latent embedding vector and there are K embedding vectors.
- z_e(x): the output of the encoder
Q) How to move to discrete latent?
A) a nearest neighbour look-up!
posterior categorical distribution
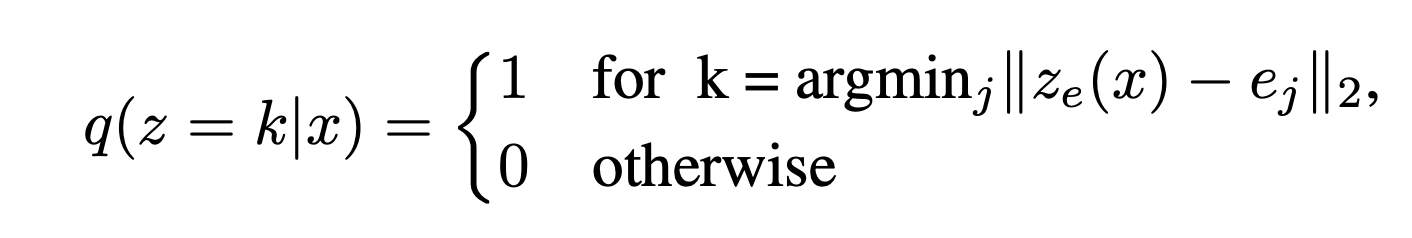
pseudo code:
def quantize(z_e, codebook):
distances = ((z_e. - codebook) ** 2).sum(-1)
indices = distances.argmin(1)
z_q = codebook[indices]
return z_q, indiceshow to update parameter with this discrete codebook?
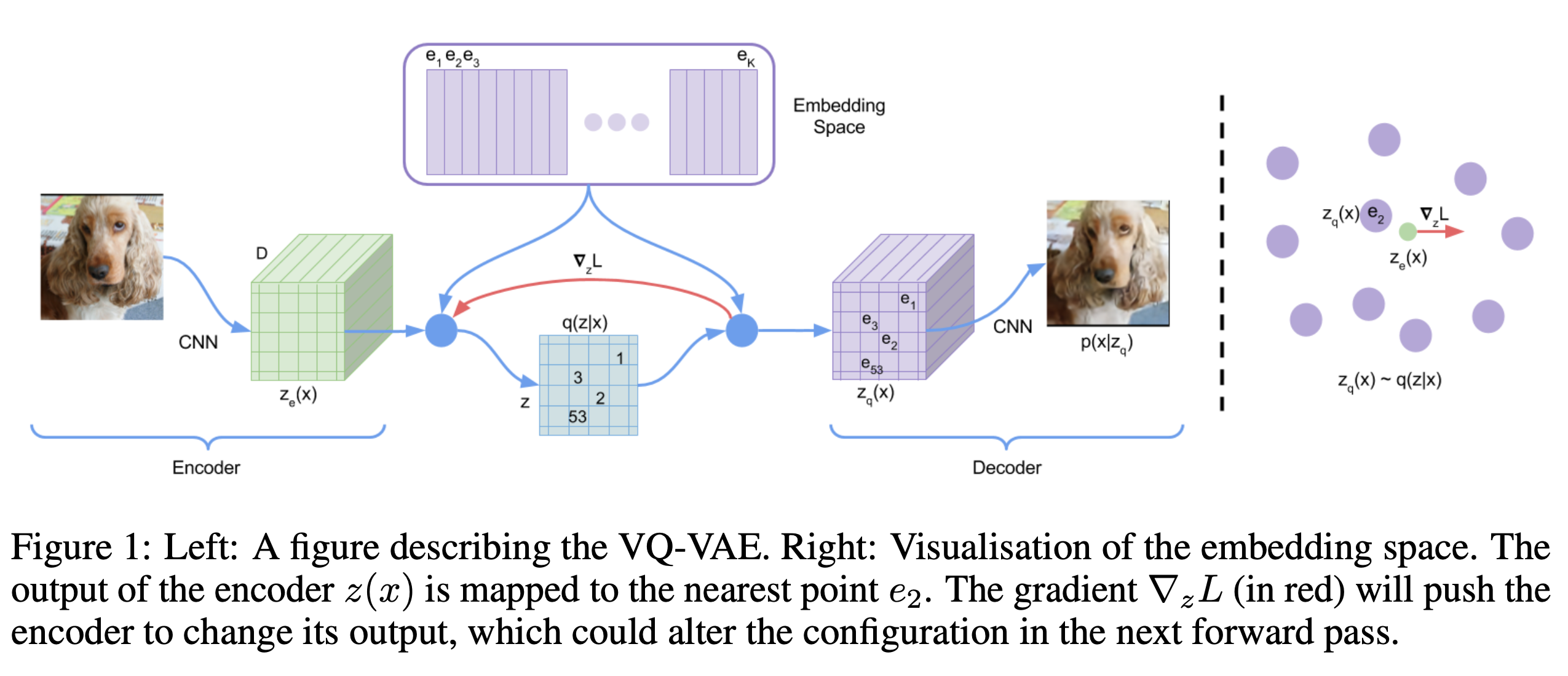
The right image means that a loss relocate the representation to other embedding vectors, then the result changes in the next process.
Loss
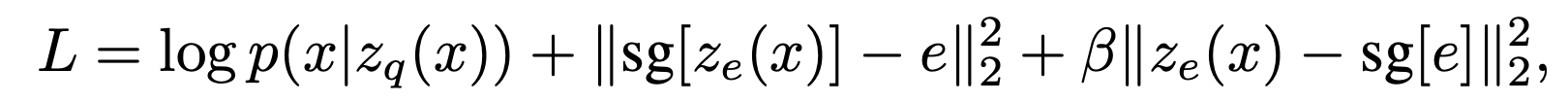
sg: stop-gradient
A first term is reconstruction loss
2nd: codebook loss
- it updates codebook vector only, moving to the encoder’s output.
3th: Commitment loss
- it updates the output of the encoder only, moving to the codebook vector.
Q) I’ve understood why does loss contains only the output of the encoder and embedding vectors (due to an non-differentiable of quantization operation). But why they are divided into two terms as codebook loss and commitment loss?
A) (The paper states that) To make sure the encoder commits to an embedding and its output does not grow, we add a commitment loss, the third term in equation
Q) Waiiiiiiiiit… the reconstruction loss contains quantization loss which is not differentiable.
A)

it just passes the gradient: STE(Straight-Through Estimator)
So… it updates the decoder and the encoder parameters, but not codebook. → codebook parameter only updates by codebook loss term.
- with PixelCNN
Original VAE practices a Gaussian distribution to sample z. When the VQ-VAE paper had written, many of researches and applications have found a better performance to exploit VAE architecture. One of them is to use PixelCNN, which models the distribution of z autoregressively. Some experiments in the paper adopt the PixelCNN to generate image with VQ-VAE.
Contribution
VQ-VAE presents a Vector-Quantization method at VAE with a codebook(embedding vector space).
4. Experiments and Results
Datasets
- ImageNet
- Reconstruction

- Reconstruction
- VCTK(The Voice Cloning Toolkit)
- 110 people’s audio samples.
- Most of them are from news or wikipedia.
- A variety of English pronounce.
Results
- 다양한 데이터 종류에 대해 적용 가능한 모델을 보여줌 (다른 표현들은 이산적이므로)
- VQ 방식을 통해 기존 VAE가 가진 posterior collapse 문제를 해결
5. Conclusions
I modified the original VAE code by simply adding the VQ process.
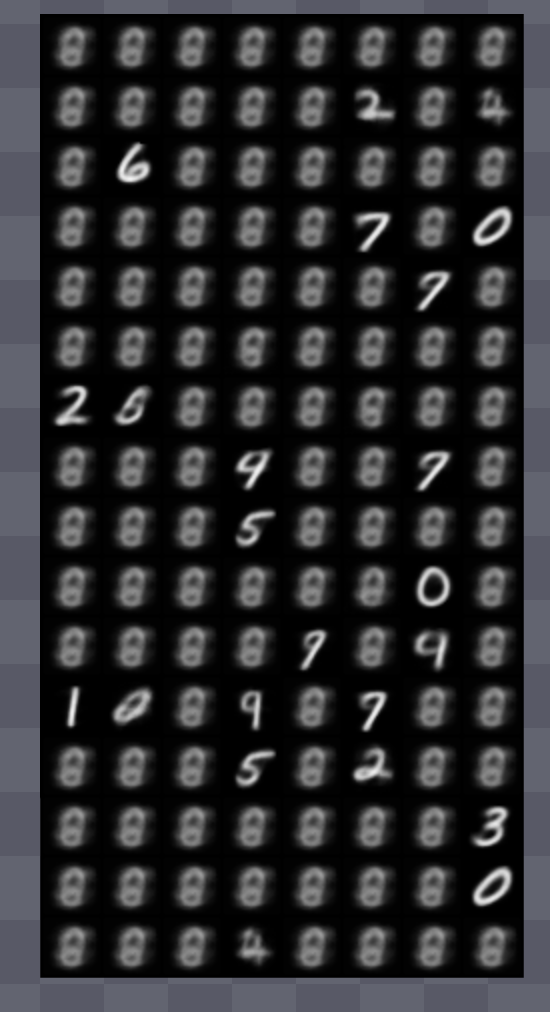
When I set the number of embeddings to 512, as used for ImageNet generation in the paper, the results weren't very good. In fact, even for the image reconstruction task, the generated images were much blurrier than those from the traditional VAE.
However, samples generated from the same embedding vector showed identical appearances.
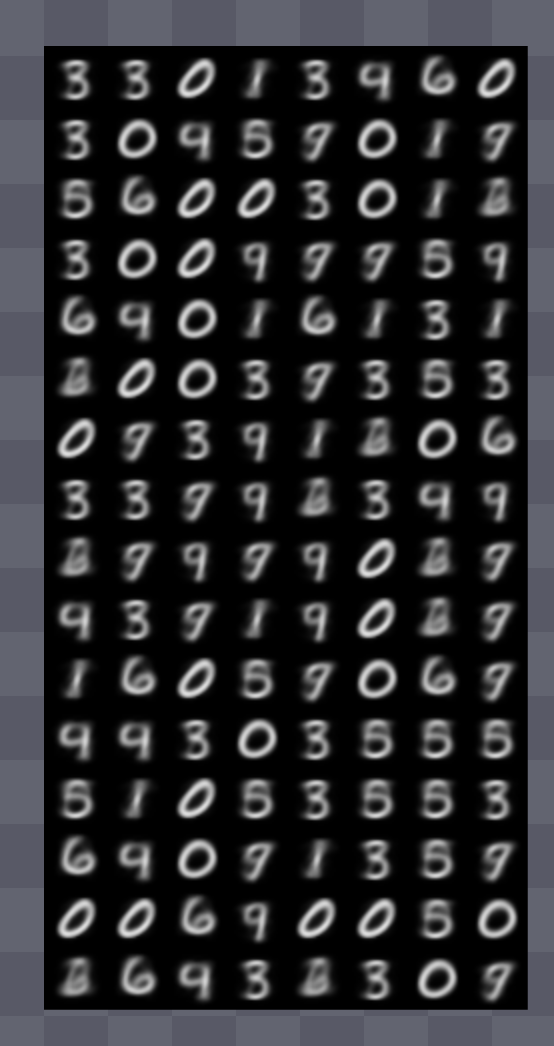
This is the result when the number of embeddings is limited to 10. It looks a bit cleaner than before.
I'm sure the results would improve if I found the right hyperparameters, but I'll just stop here!