텍스트 애널리틱스 팀 프로젝트 - LitSearch dataset Augmentation
2025-06-26
Background
팀원이 주제를 제안 - 학술 논문 Retrieval 성능을 높여보기
서칭해준 논문 및 Dataset을 바탕으로 시작.
Dataset: LitSearch 논문 링크
- S2ORC dataset에서 추출한 64000개의 paper corpus (id, title, abstract, full text) 기반
- 특정 논문을 검색하는 query를 해당 논문 저자에게 작성해달라고 요청 (Manual Query)
- 이후 LLM을 활용해 추가 생성 후, 저자들의 수작업 검수 (Inline Query)
- Query data는 논문을 검색하는 query text와 정답 논문 id label (query, paper id)
- 이 외 query에 대한 추가적인 정보 데이터들 존재
Model
- SPECTER2 - 논문 링크
- 과학 논문으로 훈련된 SciBERT checkpoint
- 논문 triplet을 이용해 임베딩 공간을 학습
- Adapter를 통해 Downstream task 수행 가능
- DPR - 논문 링크
- BERT-base model
- Dual Encoder 구조 - Question encoder | Passage encoder
- SPLADE - 논문 링크
- BERT-base model
- Sparse Search를 위해 MLM Head를 이용
- Retrieval의 흐름과 SPLADE에 대한 설명 블로그
Structure
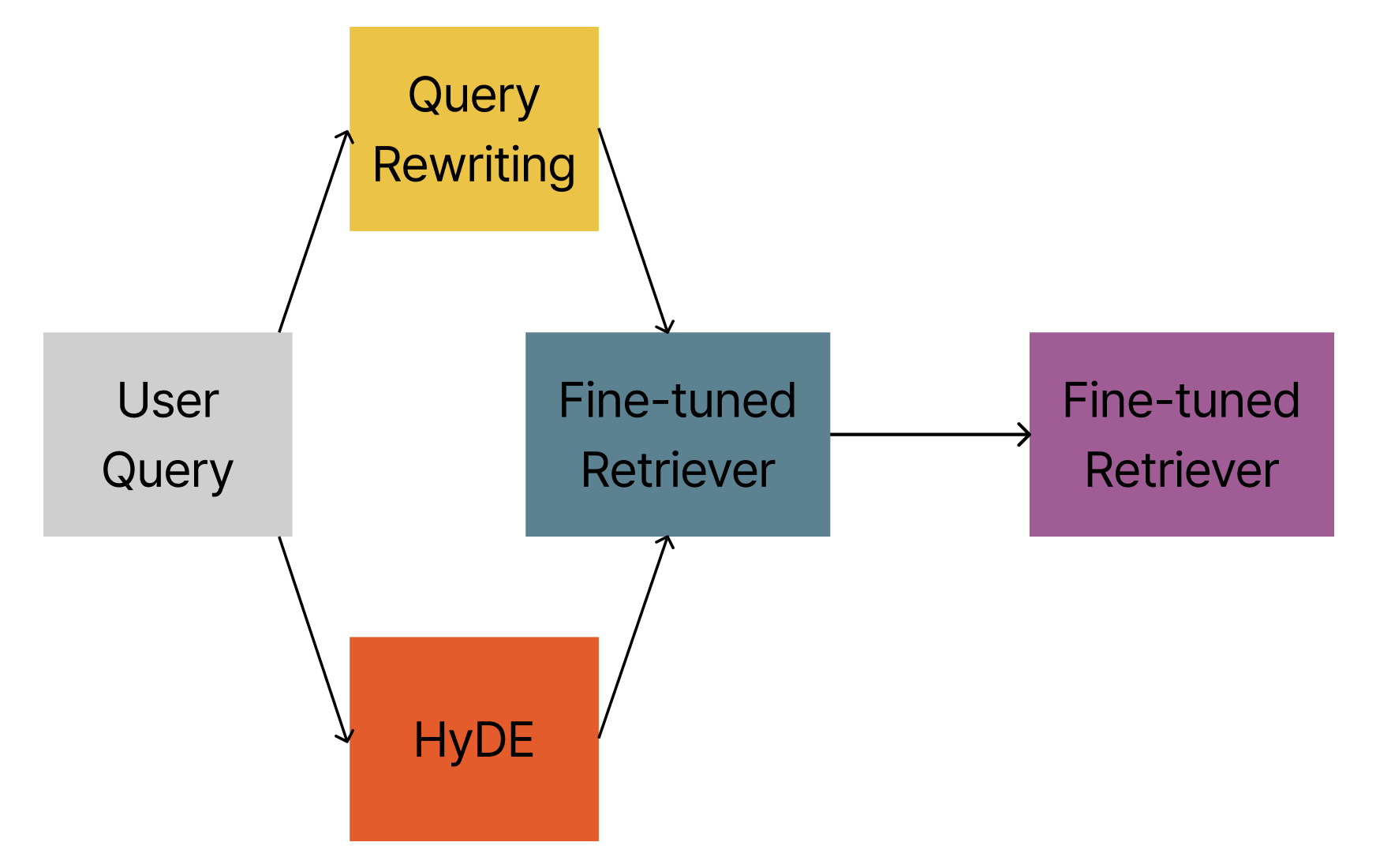
이미 성숙한 Retrieval 분야에서 LLM을 활용한 개선 방안 모색.
- Query Rewriting
- HyDE (LLM이 생성한 할루시네이션 문서를 query로 검색)
- Data Augmentation
이 중 3번, Data Augmentation(데이터 증강)을 맡아서 진행.
Why and How
Pain point
LitSearch Dataset은 많은 노동을 요구하며, 이로 인해 567개밖에 존재하지 않음
→ 실제로 Finetuning 시 과적합 문제가 발생
LitSearch 저자들이 LLM으로 생성한 Inline Query 증강 계획
- 특정 논문을 인용하는 문장인 Inline Citation Sentence를 활용
- Inline Citation Sentence를 Input으로 하여 인용되는 논문을 검색하는 쿼리 생성
파이프라인 구상
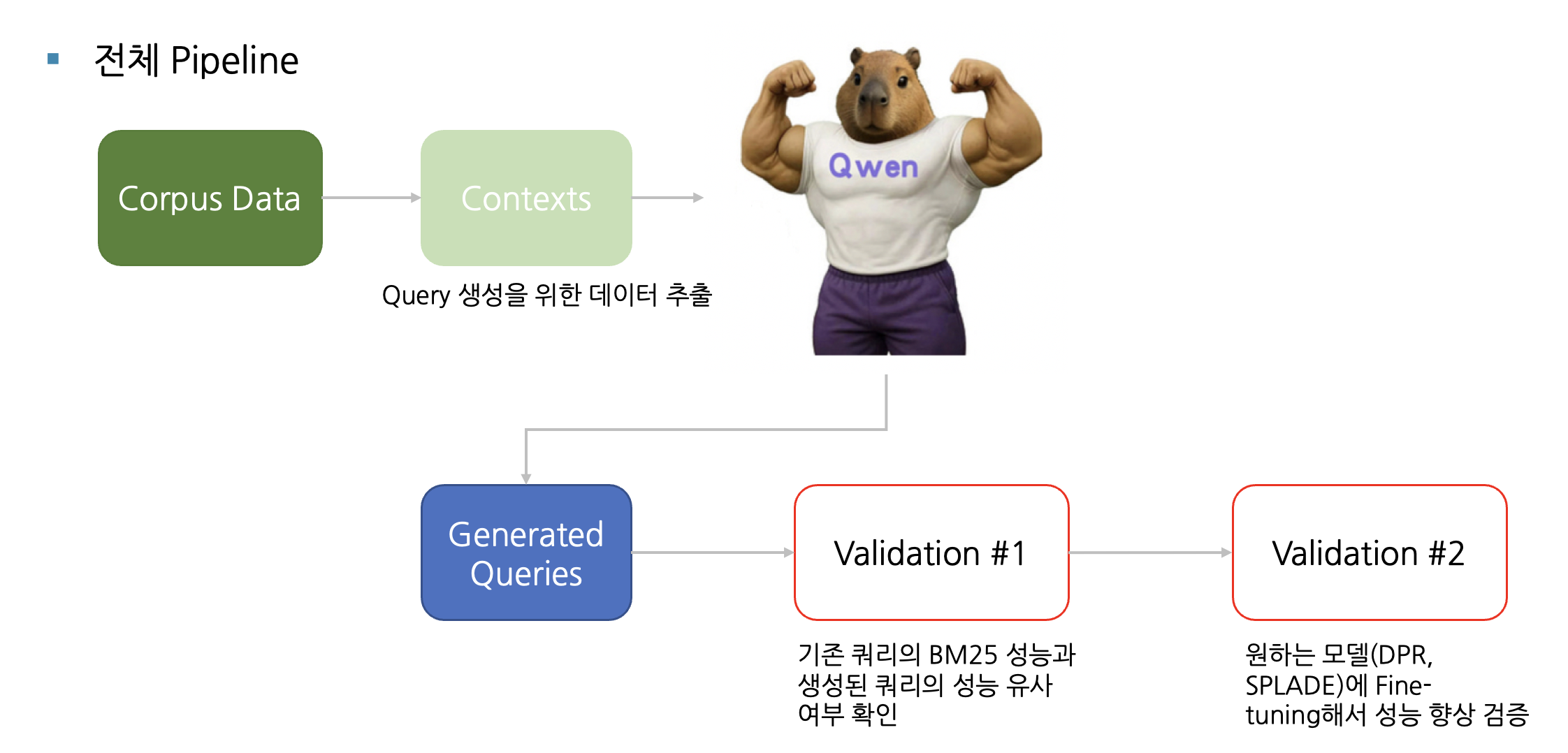
- 데이터 증강에 필요한 context data 추출 및 전처리
- Qwen3:14b 모델을 사용해 query 데이터 증강
- 증강된 데이터의 퀄리티 검증
증강 데이터 검증 방식
- BM25 recall 점수 유사도
- LitSearch dataset에서 query에 대한 여러 모델의 Retrieval 성능 존재
- 이 중 키워드 기반 Sparse Search의 근본인 BM25 점수가 증강 데이터에서 유사하게 나타나면 1차 통과
- Finetuning 후 모델의 성능 증가
- 증강 데이터로 finetuning 진행
- finetuned model이 기존 LitSearch Dataset에 대해 더 높은 성능을 보이면 최종 검증 완료
데이터 전처리 과정 (팀 프로젝트 발표 자료)


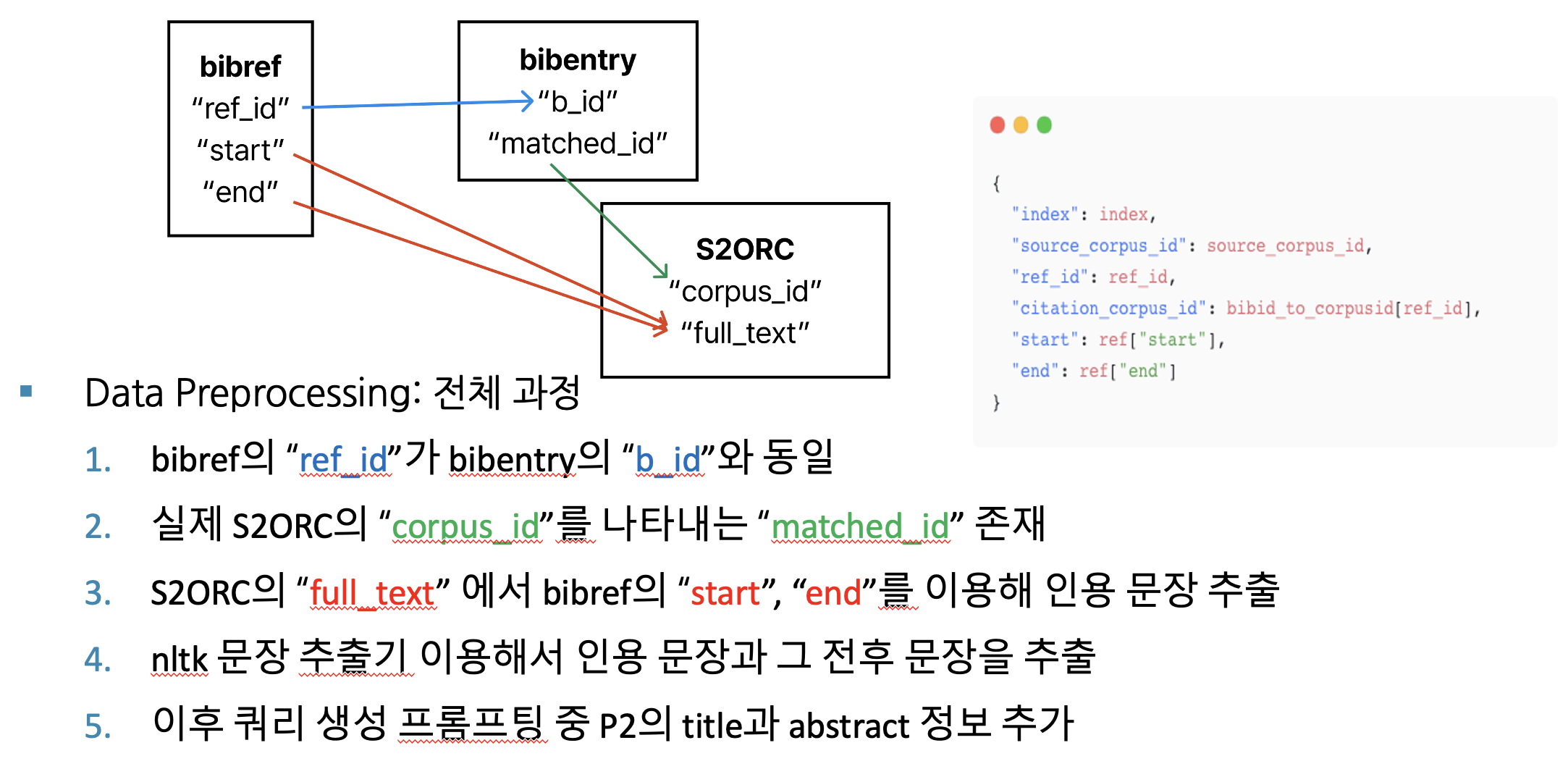


데이터 전처리와 관련된 코드는 링크 (src/data_augmentation) 중, /generate_query/extracting_ctss.py에 작성.
+ 해당 파일을 Vessl ai 내에서 컨테이너로 띄워 동작하는 extracting_ctss.yaml.
위와 동일하게 이후 과정을 로컬이나 Jupyter 환경이 아닌, py와 yml 파일을 활용하여 LLMOps 플랫폼 내에서 실행.
ㅡ
Query 생성 및 Triplet 완성
가장 최근에 출시된 좋은 성능을 가진 qwen3:14b 모델 사용.
링크 (src/data_augmentation) 모듈 및 상위 디렉토리의 data_augmentation.yaml로 실행.
쿼리 증강 프롬프트 시행착오 총 7회는 위 링크의 Prompt.md에 기록.
Data Augmentation 결과 총 1000개의 query 생성.
최종 생성된 쿼리의 BM25 Recall 20 점수는 0.429 → 기존 LitSearch 점수는 0.399로 1차 검증 통과.
SPECTER2 논문에 언급된 Easy Negative : Hard Negative = 3 : 2 비율로, 쿼리 하나당 positive 1, negative 5 쌍이 존재 → 1000개의 query로 5000개의 triplet 생성.
triplet 생성 과정은 /data_augmentation/generate_query/make_triplet/make_triplet.py에서 REPL 환경으로 진행.
Finetuning 결과
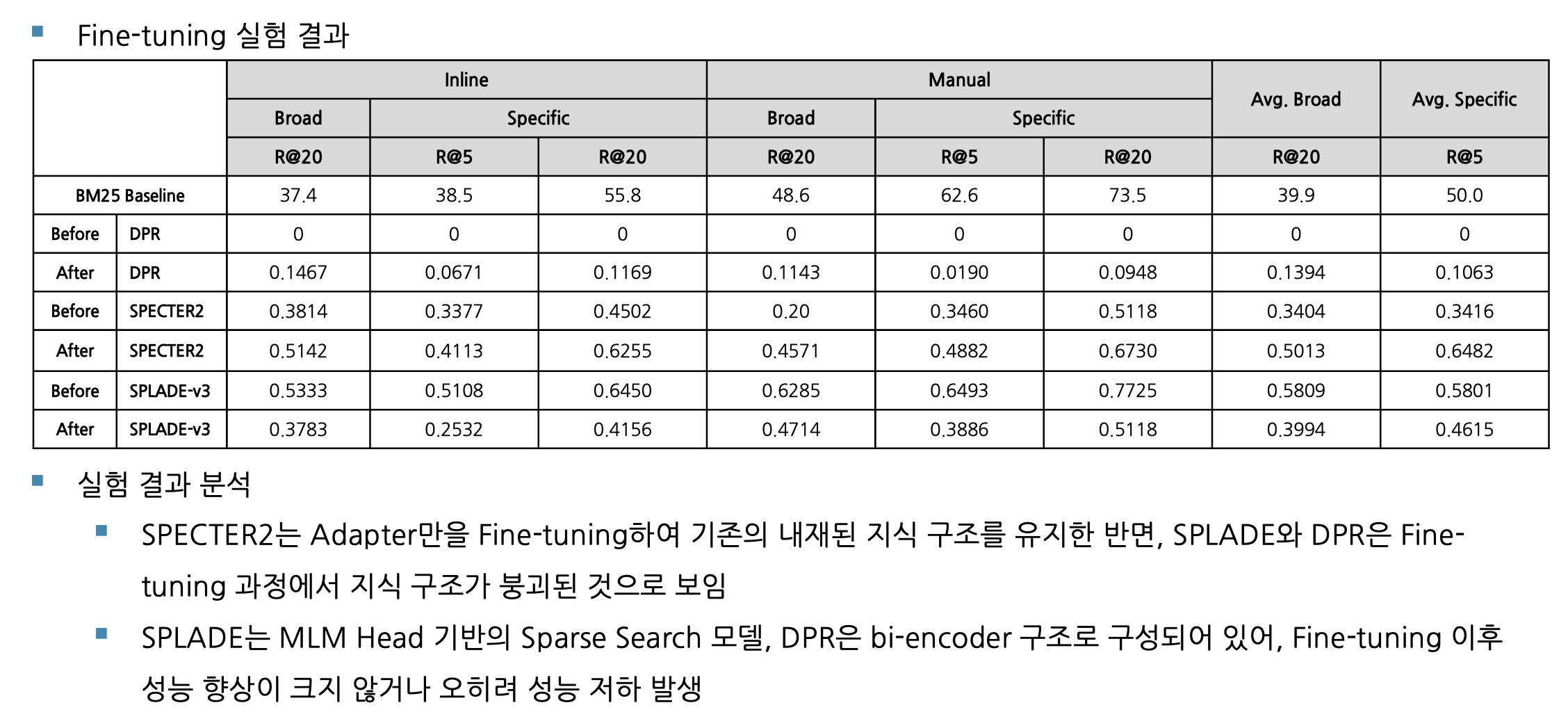
Adapter 방식을 통한 PEFT가 Retrieval embedding 모델에 효과적이라고 판단.
SPLADE-v3 모델의 성능 저하 - 모델에 대한 근본적 이해 부족
- Sparse Search가 목표인 모델에 대해 triplet으로 dense 임베딩 공간 거리를 조절하는 finetuning 방식을 적용해 지식 붕괴가 일어났다고 판단. 다만 Sparse Search에 대해서도 막연하게 성능이 좋아질 수도 있을 거란 믿음으로 진행했었음.
- 추가로 SPLADE 레포지토리에 존재하는 코드를 옮기는 과정 중, loss나 regularizer와 같은 실험 인자들을 제대로 반영하지 못함. 이 또한 성능 하락의 원인으로 추정.
Self-Reflection
데이터 전처리 및 증강 과정
증강을 위한 context data 추출에서 겪은 많은 실패가 있었다. inline citation sentence와 cited paper를 짝지어 얻는 과정부터 시간 소모가 컸는데, 이 부분도 그렇고 전 과정에서 데이터셋을 천천히 살펴보며 설계했다면 훨씬 시간을 아꼈을 듯하다. 이건 프로젝트 전체적으로도 많이 느꼈다. 코딩하기 전에 설계부터 하자.
프롬프트 엔지니어링
증강의 첫 시도가 매우 실망스러운 수준이었고, 여러 조건을 바꿔가며 진행할 때마다 점점 결과물이 좋아졌다. LLM을 다룰 때 프롬프트 엔지니어링이 얼마나 중요한지도 체감했다. 단순히 trial-error 반복이 아니라, 이전 결과를 보고 나름의 가설을 세워 다시금 프롬프트를 적용해 원하는 결과를 얻어내려면 LLM 자체에 대한 이해가 필수라 생각했다. 그리고 여러 LLM 엔지니어링 책들이 프롬프트 입출력을 로그로 남겨 모델 개선에 사용하는 이유를 확실히 깨달았다.
코드 구현
이 부분은 프로젝트에는 큰 필요가 없지만 혼자서 노력한 부분이다. 편하게 실험하도록 된 API를 쓰기보다 직접 클래스로 구현해보려 했고, 무엇보다 Jupyter Notebook이 아닌 Vessl AI에서 container를 띄우는 yml 파일을 작성해 실행시키려 했다. 이 과정에서 수많은 Failed를 마주하고 디버깅할 때 코드의 근본적인 문제가 있음을 깨달았다. 기능들이 올바르게 분리되어 있지 않고 하나의 클래스에 몰려있는 점, 로그부터 assertion, error handling 등등. 프론트와 근본적으로 다른 코드 구조를 가져가야 함을 run 돌릴 때 확실히 깨달았다. 아래는 finetuning만을 위해 70번 넘게 Run을 돌린 흔적. 일단 실패하고, 로그 보고 조금씩 고치다보니 저렇게 됐다.
Future Direction
모델에 대한 이해
모델에 대한 논문을, 특히 모델 설계와 실험 조건 및 과정 부분을 자세히 읽고 활용했을 듯하다. 이를 간과하고 무작정 코딩하다 시간을 더 소모하기도 했고, 애초에 잘못된 설계를 하기도 했다. 특히 SPLADE를 제대로 활용하지 못한 점이 너무 아쉬웠다. 다음 번에는 천천히 모델의 특징을 알아보고 적절한 방법론을 채택해보려 노력해볼 것이다.
지저분한 코드
SPLADE 모델 코드를 보면서 반성을 많이 했다. 유지보수와 디버깅이 용이하도록 추상화, 분리하는 과정이 필요하고, 그 전에 기본적으로 파이썬이란 언어를 좀 더 잘 이해할 필요도 있다.